Tenemos todas las herramientas para buscar, captar y generar clientes.
Queremos brindarte una solución integral que te permita incrementar tu negocio, reduciendo la distancia entre tu empresa y tu potencial clientes. Para esto incorporamos constantemente nuevas herramientas para que el desarrollo de nuevos vínculos comerciales sean posibles.
Las técnicas de comercialización deben entonces cambiar su paradigma. Somos una agencia moderna y pensamos en una estrategia digital que ayude a las empresas a demostrar su valor y generar ventas utilizando todas las vías posibles.
Nuestros clientes son nuestra mejor presentación
The provided API key is expired.
CONTACTO
Esperamos tus consulta
Tu visibilidad está a un email de distancia
BUENOS AIRES, ARGENTINA
AV. CASEROS 715- 1D
Nuestro Blog

Máster en Innovación y Emprendimiento + Máster en Hotelería y Turismo
Presentación El Máster en Innovación y Emprendimiento + Máster en Hotelería y Turismo tiene como objetivo profundizar en las claves para poner en marcha una compañía, con énfasis en el…

¿Cómo aumentar la visibilidad en Linkedin?
Construyendo tu marca Si tu mensaje, tu producto o servicio e incluso tu perfil (por muy impresionante que sean) no llegan a la audiencia adecuada, no servirá de nada. Es por…







RECOMENDADO: Haga clic aquí para corregir errores de Windows y aprovechar al máximo el rendimiento del sistema Los usuarios de la plataforma del sistema operativo Windows 10 pueden hallar este…
R Marketing Digital20/09/2022

RECOMENDADO: Haga clic aquí para corregir errores de Windows y aprovechar al máximo el rendimiento del sistema Logitech ha trabajado duro en los últimos años para recuperar a la multitud…
R Marketing Digital19/09/2022
RECOMENDADO: Haga clic aquí para corregir errores de Windows y aprovechar al máximo el rendimiento del sistema ¿Obtiene el error 0xc10100bf al leer archivos? ¡Llegaste al lugar correcto! Este post…
R Marketing Digital05/10/2022
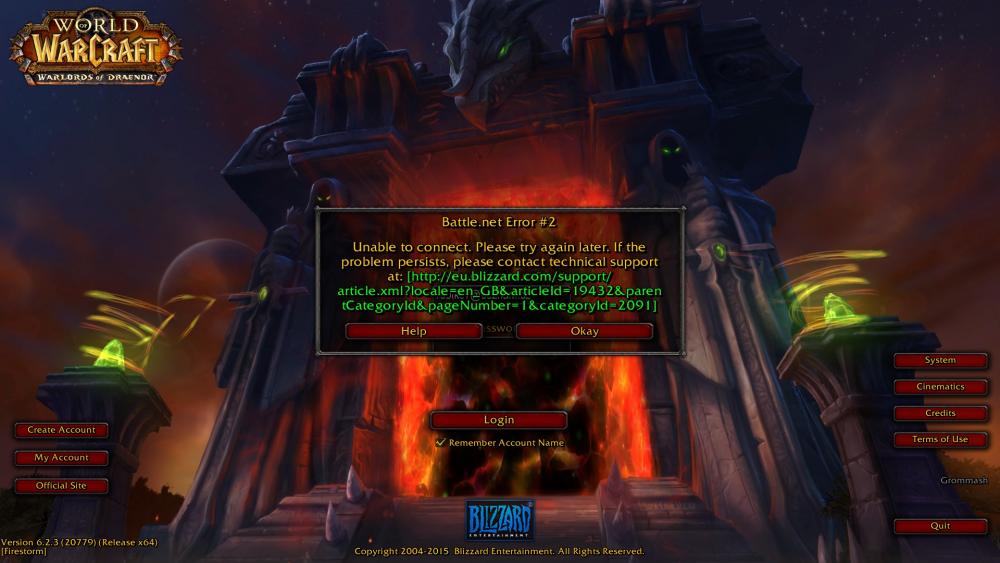
RECOMENDADO: Haga clic aquí para corregir errores de Windows y aprovechar al máximo el rendimiento del sistema El error Battle.net Error # 2 de forma general ocurre cuando algunos usuarios…
R Marketing Digital04/09/2022
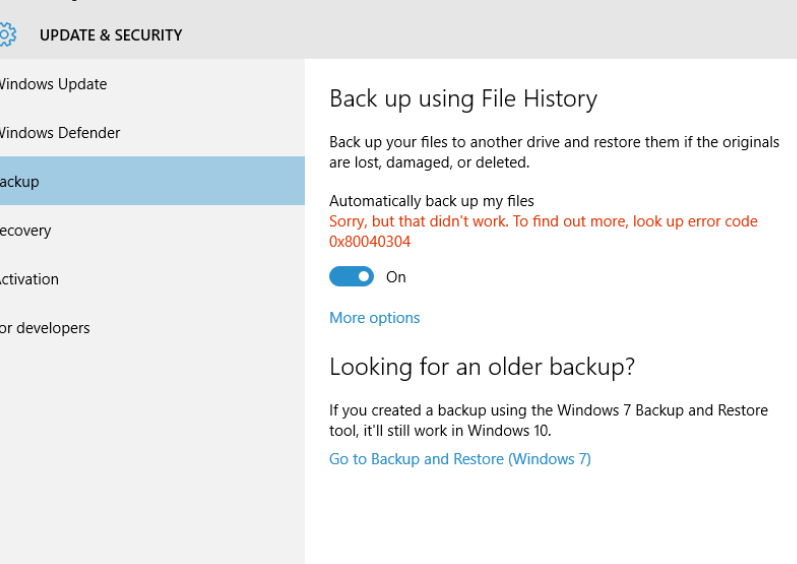
RECOMENDADO: Haga clic aquí para corregir errores de Windows y aprovechar al máximo el rendimiento del sistema El código de error 0x80040304 puede llegar a cientos de usuarios todos los…
R Marketing Digital03/09/2022

Las versiones de Office son mucho más compatibles que las de Windows. A modo de ejemplo, la versión 2010 de esta suite ofimática seguirá recibiendo actualizaciones hasta octubre de 2020…
R Marketing Digital06/08/2022
Redes sociales
No puedo compartir fotos de Instagram en la página de fanáticos. ¿Cómo lo soluciono?
Una de las cosas que más se repiten cuando hablamos de promocionar tu perfil de Instagram es aprovechar los followers y contactos que ya tienes en otras redes sociales. Compartir…
¿Qué hacer cuando alguien roba tu foto en Instagram?
Hace unos días un seguidor del blog se puso en contacto con nosotros explicando que otra persona había tomado una foto de su cuenta de Instagram y posteriormente la había…