Cómo establecer el cuello de botella de un servidor, solucionarlo rápidamente, mejorar el rendimiento del servidor y prevenir regresiones.
Visión general
Esta guía le muestra cómo reparar un servidor sobrecargado en 4 pasos:
- Examinar: determine el cuello de botella del servidor.
- Estabilizar: implemente soluciones rápidas para mitigar el impacto.
- Mejorar: Aumente y optimice las capacidades del servidor.
- Supervisar: utilice herramientas automatizadas para ayudar a prevenir problemas futuros.
Si tiene preguntas o comentarios sobre esta guía, o si desea compartir sus propios consejos y trucos, deje un comentario en PR # 2479.
Examinar
Cuando el tráfico sobrecarga un servidor, uno o más de los siguientes pueden convertirse en un cuello de botella: CPU, red, memoria o E / S de disco. Identificar cuál de estos es el cuello de botella posibilita concentrar los esfuerzos en las mitigaciones más impactantes.
- CPU: se debe investigar y corregir el uso de CPU que sea consistentemente superior al 80%. El rendimiento del servidor muchas veces se degrada una vez que el uso de la CPU cumple ~ 80-90%, y se torna más pronunciado cuando el uso se acerca al 100%. La utilización de la CPU para atender una sola solicitud es insignificante, pero hacerlo a la escala que se encuentra durante los picos de tráfico a veces puede abrumar a un servidor. La descarga del servicio a otra infraestructura, la disminución de operaciones costosas y la limitación de la cantidad de solicitudes reducirán la utilización de la CPU.
- Red: durante períodos de alto tráfico, el rendimiento de la red necesario para satisfacer las solicitudes de los usuarios puede exceder la capacidad. Algunos sitios, dependiendo del proveedor de hosting, además pueden tener límites en cuanto a la transferencia de datos acumulativos. Disminuir el tamaño y la cantidad de datos transferidos hacia y desde el servidor eliminará este cuello de botella.
- Memoria: cuando un sistema no tiene suficiente memoria, los datos deben descargarse en el disco para su almacenamiento. El acceso al disco es considerablemente más lento que a la memoria, y esto puede ralentizar una aplicación completa. Si la memoria se agota por completo, puede resultar en Sin memoria (OOM) errores. Ajustar la asignación de memoria, solucionar las pérdidas de memoria y actualizar la memoria puede borrar este cuello de botella.
- E / S de disco: la velocidad a la que se pueden leer o escribir datos desde el disco está restringida por el propio disco. Si la E / S de disco es un cuello de botella, incrementar la cantidad de datos almacenados en la memoria caché puede aliviar este problema (a costa de una mayor utilización de la memoria). Si esto no funciona, puede que sea necesario actualizar sus discos.
Las técnicas de esta guía se enfocan en abordar los cuellos de botella de la CPU y la red. Para la mayoría de los sitios, la CPU y la red serán los cuellos de botella más relevantes durante un pico de tráfico.
Corriendo top en el servidor afectado es un buen punto de partida para investigar los cuellos de botella. Si se encuentra disponible, complemente esto con datos históricos de su proveedor de hosting o herramientas de monitoreo.
Estabilizar
Un servidor sobrecargado puede conducir rápidamente a fallas en cascada en otras partes del sistema. De esta manera, es esencial estabilizar el servidor antes de intentar realizar cambios más significativos.
Limitación de tasa
La limitación de velocidad protege la infraestructura al limitar la cantidad de solicitudes entrantes. Esto es cada vez más importante a medida que se degrada el rendimiento del servidor: a medida que aumentan los tiempos de respuesta, los usuarios tienden a actualizar la página agresivamente, lo que aumenta todavía más la carga del servidor.
Reparar
Aunque rechazar una solicitud es relativamente económico, la mejor manera de proteger su servidor es manejar la limitación de velocidad en algún lugar aguas arriba, a modo de ejemplo, mediante un equilibrador de carga, proxy inverso o CDN.
Instrucciones:
Otras lecturas:
Almacenamiento en caché HTTP
Busque alternativas para almacenar en caché el contenido de manera más agresiva. Si un recurso se puede servir desde una caché HTTP (ya sea la caché del navegador o una CDN), entonces no hace falta solicitarlo desde el servidor de origen, lo que reduce la carga del servidor.
Encabezados HTTP como Cache-Control, Expiresy ETag indicar cómo un recurso debe almacenarse en caché a través de una caché HTTP. Auditar y corregir estos encabezados mejorará el almacenamiento en caché.
Pese a que empleados de servicio además se pueden usar para el almacenamiento en caché, usan un cache y son un complemento, más que un reemplazo, del almacenamiento en caché HTTP adecuado. Por esta razón, al manejar un servidor sobrecargado, los esfuerzos deben centrarse en aprovechar al máximo el almacenamiento en caché HTTP.
Diagnosticar
correr Faro y mira el Sirva activos estáticos con una política de caché eficiente auditar para ver una lista de recursos con un corto a medio tiempo para vivir (TTL). Para cada recurso enumerado, considere si se debe incrementar el TTL. Como pauta aproximada:
- Los recursos estáticos deben almacenarse en caché con un TTL largo (1 año).
- Los recursos dinámicos deben almacenarse en caché con un breve TTL (3 horas).
Reparar
Selecciona el Cache-Control encabezado max-age directiva al número apropiado de segundos.
Instrucciones:
Nota la max-age La directiva es solo una de las muchas directivas de almacenamiento en caché. Hay muchas otras directivas y encabezados que afectarán el comportamiento de almacenamiento en caché de su aplicación. Para conseguir una explicación más detallada de la estrategia de almacenamiento en caché, se recomienda encarecidamente que lea Almacenamiento en caché HTTP.
Degradación elegante
La degradación elegante es la estrategia de disminuir temporalmente la funcionalidad para borrar el exceso de carga de un sistema. Este concepto se puede aplicar de muchas formas diferentes: a modo de ejemplo, publicando una página de texto estático en vez de una aplicación con todas las funciones, desactivando la búsqueda o devolviendo menos resultados de búsqueda, o desactivando ciertas funciones caras o no esenciales. Se tiene que hacer hincapié en borrar las funcionalidades que pueden eliminarse de forma segura y sencilla con un impacto comercial mínimo.
Mejorar
Utilice una red de entrega de contenido (CDN)
El servicio de activos estáticos se puede descargar desde su servidor a una red de entrega de contenido (CDN), reduciendo así la carga.
La función principal de una CDN es entregar contenido a los usuarios rápidamente al proporcionar una gran red de servidores que se encuentran cerca de los usuarios. A pesar de todo, la mayoría de las CDN además ofrecen funciones adicionales asociadas con el rendimiento, como compresión, equilibrio de carga y optimización de medios.
Configurar una CDN
Las CDN se benefician de la escala, por lo que operar su propia CDN rara vez tiene sentido. Una configuración básica de CDN es bastante rápida de configurar (~ 30 minutos) y se trata de actualizar los registros DNS para apuntar a la CDN.
Aprovechar al máximo el uso de CDN
Diagnosticar
Identifique los recursos que no están siendo servidos desde una CDN (pero deberían serlo) ejecutando WebPageTest. En la página de resultados, haga clic en el cuadro de arriba ‘Uso efectivo de CDN’ para ver el listado de recursos que deberían ser servidos desde un CDN.
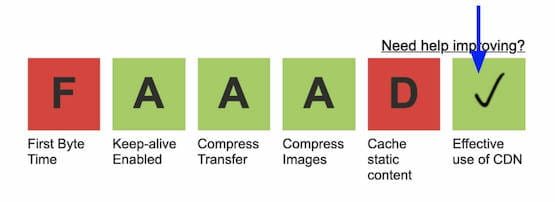
Resultados de WebPageTest
Reparar
Si la CDN no almacena en caché un recurso, verifique que se cumplan las siguientes condiciones:
Escale los recursos informáticos
La decisión de escalar los recursos informáticos debe tomarse con cuidado. Aún cuando muchas veces hace falta escalar los recursos informáticos, hacerlo prematuramente puede generar complejidad arquitectónica y costos financieros innecesarios.
Diagnosticar
Un tiempo hasta el primer byte alto (TTFB) puede ser una señal de que un servidor está llegando a su capacidad. Puedes hallar esta información en el Faro Disminuir los tiempos de respuesta del servidor (TTFB) auditoría.
Para investigar más, use una herramienta de monitoreo para examinar el uso de la CPU. Si el uso de CPU actual o anticipado excede el 80%, debería considerar incrementar sus servidores.
Reparar
Agregar un equilibrador de carga posibilita repartir el tráfico entre varios servidores. Un equilibrador de carga se encuentra frente a un grupo de servidores y enruta el tráfico al servidor apropiado. Los proveedores de la nube ofrecen sus propios equilibradores de carga (GCP, AWS, Azur) o puede configurar el suyo propio utilizando HAProxy o NGINX. Una vez que se haya implementado un equilibrador de carga, se pueden agregar servidores adicionales.
Al mismo tiempo del equilibrio de carga, la mayoría de los proveedores de nube ofrecen ajuste de escala automático (GCP, AWS, Azur). El ajuste de escala automático funciona junto con el equilibrio de carga: el ajuste de escala automático escala de forma automática los recursos informáticos hacia arriba y hacia abajo según la demanda en un momento determinado. Una vez dicho esto, el ajuste de escala automático no es mágico: se requiere tiempo para que las nuevas instancias estén en línea y necesita una configuración significativa. Debido a la complejidad adicional que conlleva el ajuste de escala automático, primero se debe considerar una configuración más simple basada en el balanceador de carga.
Habilitar la compresión
Los recursos basados en texto deben comprimirse a través de gzip o brotli. Gzip puede disminuir el tamaño de transferencia de estos recursos en aproximadamente un 70%.
Diagnosticar
Utiliza el faro Habilitar la compresión de texto auditoría para identificar los recursos que deben comprimirse.
Reparar
Habilite la compresión actualizando la configuración de su servidor. Instrucciones:
Aprovechar al máximo imágenes y medios
Las imágenes constituyen la mayor parte del tamaño de archivo de la mayoría de los sitios web; La optimización de imágenes puede disminuir rápida y significativamente el tamaño de un sitio.
Diagnosticar
Lighthouse cuenta con una variedad de auditorías que señalan posibles optimizaciones de imagen. Alternativamente, otra estrategia es usar DevTools para identificar los archivos de imagen más grandes; estas imágenes probablemente serán buenas candidatas para la optimización.
Auditorías de Lighthouse relevantes:
Flujo de trabajo de Chrome DevTools:
Reparar
Si dispones de tiempo limitado …
Concentre su tiempo en identificar imágenes grandes y cargadas muchas veces y optimizarlas manualmente con una herramienta como Squoosh. Las imágenes heroicas generalmente son buenas candidatas para la optimización.
Cosas a prestar atención:
- Tamaño: las imágenes no deben ser más grandes de lo primordial.
- Compresión: en términos generales, un nivel de calidad de 80-85 tendrá un efecto mínimo en la calidad de la imagen, mientras que producirá una disminución del 30-40% en el tamaño del archivo.
- Formato: use JPEG para fotos en vez de PNG; use MP4 para contenido animado en vez de GIF.
Si dispones de más tiempo …
Considere la oportunidad de configurar una CDN de imágenes si las imágenes constituyen una parte sustancial de su sitio. Las CDN de imágenes están diseñadas para servir y aprovechar al máximo imágenes y descargarán el servicio de imágenes desde el servidor de origen. Configurar una CDN de imagen es sencillo, pero necesita actualizar las URL de imagen existentes para que apunten a la CDN de imagen.
Otras lecturas:
Minificar JS y CSS
La minificación elimina los caracteres innecesarios de JavaScript y CSS.
Diagnosticar
Usar el Minificar CSS y Minify las auditorías de JavaScript Lighthouse para identificar los recursos que necesitan minificación.
Reparar
Si tiene tiempo limitado, concéntrese en minimizar su JavaScript. La mayoría de los sitios disponen más JavaScript que CSS, por lo que esto tendrá más impacto.
Monitor
Las herramientas de supervisión del servidor proporcionan recopilación de datos, paneles y alertas sobre el rendimiento del servidor. Su uso puede ayudar a prevenir y mitigar problemas futuros de rendimiento del servidor.
Una configuración de monitoreo debe mantenerse lo más simple factible. La recopilación y alerta excesiva de datos tiene sus costos: cuanto mayor es el alcance o la frecuencia de la recopilación de datos, más costoso es recabar y almacenar; una alerta excesiva conduce inevitablemente a páginas ignoradas.
Las alertas deben utilizar métricas que detecten problemas de manera consistente y precisa. El tiempo de respuesta del servidor (latencia) es una métrica que funciona concretamente bien para ello: detecta una amplia variedad de problemas y se correlaciona de forma directa con la experiencia del usuario. Las alertas sustentadas en métricas de nivel inferior, como el uso de la CPU, pueden ser un complemento útil, pero detectarán un subconjunto más pequeño de problemas. Al mismo tiempo, las alertas deben basarse en el desempeño observado en la cola (dicho de otra forma, los percentiles 95 o 99), en vez de promedios. Caso contrario, los promedios pueden esconder fácilmente problemas que no impactan a todos los usuarios.
Reparar
Todos los principales proveedores de nube ofrecen sus propias herramientas de monitoreo (GCP, AWS, Azur). Adicionalmente, Netdata es una magnífica alternativa gratuita y open source. Sin tener en cuenta la herramienta que elija, deberá instalar el agente de supervisión de la herramienta en cada servidor que desee supervisar. Una vez completado, asegúrese de configurar las alertas.
Instrucciones: