Cómo establecer el cuello de botella de un server, solucionarlo rápidamente, mejorar el rendimiento del servidor y prevenir regresiones.
Overview
This guide shows you how to repair an overloaded server in 4 steps:
- Browse - Determine the server bottleneck.
- Stabilize - Implement quick fixes to mitigate the impact.
- Upgrade: Increase and optimize server capabilities.
- Monitor - Use automated tools to help prevent future problems.
If you have questions or comments about this guide, or if you want to share your own tips and tricks, please leave a comment on PR # 2479.
Examine
When the traffic sobrecarga un servidor, uno o más de los siguientes pueden convertirse en un cuello de botella: CPU, red, memoria o E / S de disco. Identificar cuál de estos es el cuello de botella posibilita concentrar los esfuerzos en las mitigaciones más impactantes.
- CPU: se debe investigar y corregir el uso de CPU que be consistentemente superior al 80%. El rendimiento del servidor muchas veces se degrada una vez que el uso de la CPU cumple ~ 80-90%, y se torna más pronunciado cuando el uso se acerca al 100%. La utilización de la CPU para atender una sola solicitud es insignificante, pero hacerlo a la escala que se encuentra durante los picos de tráfico a veces puede abrumar a un servidor. La descarga del servicio a otra infraestructura, la disminución de operaciones costosas y la limitación de la cantidad de solicitudes reducirán la utilización de la CPU.
- Network - During periods of high traffic, the network performance required to meet user requests may exceed capacity. Some sites, depending on the hosting provider, may also have cumulative data transfer limits. Decreasing the size and amount of data transferred to and from the server will eliminate this bottleneck.
- Memory - When a system does not have enough memory, data must be downloaded to disk for storage. Disk access is considerably slower than memory, and this can slow down an entire application. If memory runs out completely, it may result in Without memory (OOM) errors. Adjusting memory allocation, troubleshooting memory leaks, and upgrading memory can clear this bottleneck.
- E / S de disco: la velocidad a la que se pueden leer o escribir datos desde el disco está restringida por el propio disco. Si la E / S de disco es un cuello de botella, incrementar la cantidad de datos almacenados en la memoria cache puede aliviar este problema (a costa de una mayor utilización de la memoria). Si esto no funciona, puede que sea necesario actualizar sus discos.
The techniques in this guide focus on addressing CPU and network bottlenecks. For most sites, the CPU and network will be the most significant bottlenecks during a traffic spike.
In a hurry top on the affected server is a good starting point for investigating bottlenecks. If available, supplement this with historical data from your hosting provider or monitoring tools.
Stabilize
An overloaded server can quickly lead to cascading faults in other parts of the system. Thus, it is essential to stabilize the server before attempting to make more significant changes.
Rate limitation
Rate capping protects the infrastructure by limiting the number of incoming requests. This becomes increasingly important as server performance degrades - as response times increase, users tend to aggressively refresh the page, further increasing server load.
Repair
Although rejecting a request is relatively inexpensive, the best way to protect your server is to handle rate throttling somewhere upstream, for example using a load balancer, reverse proxy, or CDN.
Instructions:
Other readings:
Caching HTTP
Busque alternativas para almacenar en caché el contents de manera más agresiva. Si un recurso se puede servir desde una caché HTTP (ya sea la caché del browser o una CDN), entonces no hace falta solicitarlo desde el servidor de origen, lo que reduce la carga del servidor.
Headers HTTP como Cache-Control, Expireand ETag indicate how a resource should be cached through an HTTP cache. Auditing and correcting these headers will improve caching.
Although service employees furthermore they can be used for caching, they use a cache and they are a complement, rather than a replacement, for proper HTTP caching. For this reason, when handling an overloaded server, efforts should be focused on making the most of HTTP caching.
To diagnose
to run Lighthouse and look at the Serve static assets with an efficient cache policy audit to see a list of resources with a short to medium time to live (TTL). For each resource listed, consider whether the TTL should be increased. As a rough guideline:
- Static resources must be cached with a long TTL (1 year).
- Dynamic resources should be cached with a short TTL (3 hours).
Repair
Select the Cache-Control header max-age directive to the appropriate number of seconds.
Instructions:
Note the max-age La directiva es solo una de las muchas directivas de almacenamiento en caché. Hay muchas otras directivas y encabezados que afectarán el comportamiento de almacenamiento en caché de su aplicación. Para conseguir una explicación más detallada de la strategy de almacenamiento en caché, se recomienda encarecidamente que lea HTTP caching.
Elegant degradation
Graceful demotion is the strategy of temporarily decreasing functionality to erase excess load from a system. This concept can be applied in many different ways: by way of example, by publishing a static text page instead of a full-featured application, by disabling search or returning fewer search results, or by disabling certain expensive or nonessential features. Emphasis has to be placed on deleting functionalities that can be safely and easily removed with minimal business impact.
To get better
Use a content delivery network (CDN)
The static asset service can be downloaded from your server to a content delivery network (CDN), thus reducing the load.
The primary function of a CDN is to deliver content to users quickly by providing a large network of servers that are close to the users. Regardless, most CDNs also offer additional features associated with performance, such as compression, load balancing, and media optimization.
Set up a CDN
Las CDN se benefician de la escala, por lo que operar su propia CDN rara vez tiene sentido. Una configuración básica de CDN es bastante rápida de configurar (~ 30 minutos) y se trata de actualizar los registros DNS para apuntar a la CDN.
Get the most out of CDN usage
To diagnose
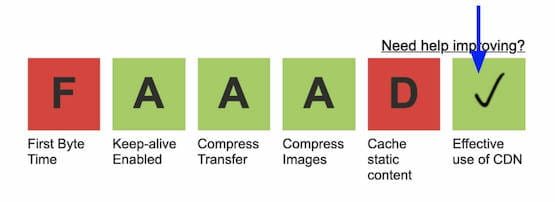
Identify resources that are not being served from a CDN (but should be) by running WebPageTest. On the results page, click on the box above 'Effective CDN use' to see the list of resources that should be served from a CDN.
WebPageTest Results
Repair
If the CDN does not cache a resource, verify that the following conditions are met:
Scale computing resources
The decision to scale computing resources must be made carefully. Even though computing resources often need to be scaled, doing so prematurely can lead to unnecessary architectural complexity and financial costs.
To diagnose
A time to first high byte (TTFB) can be a sign that a server is reaching capacity. You can find this information in the Lighthouse Decrease server response times (TTFB) audit.
To investigate further, use a monitoring tool to examine CPU usage. If your current or anticipated CPU usage exceeds 80%, you should consider increasing your servers.
Repair
Adding a load balancer makes it possible to spread traffic across multiple servers. A load balancer faces a group of servers and routes traffic to the appropriate server. Cloud providers offer their own load balancers (GCP, AWS, Azure) or you can configure your own using HAProxy or NGINX. After a load balancer has been deployed, additional servers can be added.
At the same time as load balancing, most cloud providers offer autoscaling (GCP, AWS, Azure). Autoscaling works in conjunction with load balancing: Autoscaling automatically scales compute resources up and down based on demand at a given time. Having said that, autoscaling isn't magic - it takes time for new instances to come online, and it takes significant setup. Due to the additional complexity involved in autoscaling, a simpler load balancer-based configuration should be considered first.
Enable compression
Text-based resources must be compressed via gzip or brotli. Gzip can decrease the transfer size of these resources by approximately 70%.
To diagnose
Use the lighthouse Enable text compression audit to identify the resources to be compressed.
Repair
Enable compression by updating your server settings. Instructions:
Make the most of images and media
Images make up the majority of the file size of most websites; Image optimization can quickly and significantly decrease the size of a site.
To diagnose
Lighthouse has a variety of audits that point to possible image optimizations. Alternatively, another strategy is to use DevTools to identify the largest image files; these images will probably be good candidates for optimization.
Relevant Lighthouse Audits:
Chrome DevTools workflow:
Repair
If you have limited time ...
Focus your time on identifying large and multi-loaded images and manually optimizing them with a tool like Squoosh. Heroic images are generally good candidates for optimization.
Things to pay attention to:
- Size: the images should not be larger than the main thing.
- Compresión: en términos generales, un quality level de 80-85 tendrá un efecto mínimo en la calidad de la imagen, mientras que producirá una disminución del 30-40% en el tamaño del archivo.
- Format: use JPEG for photos instead of PNG; use MP4 for animated content instead of GIF.
If you have more time ...
Considere la oportunidad de configurar una CDN de imágenes si las imágenes constituyen una parte sustancial de su sitio. Las CDN de imágenes están diseñadas para servir y aprovechar al máximo imágenes y descargarán el servicio de imágenes desde el servidor de origen. Configurar una CDN de imagen es sencillo, pero necesita actualizar las Url de imagen existentes para que apunten a la CDN de imagen.
Other readings:
Minificar JS y CSS
La minificación elimina los caracteres innecesarios de JavaScript y CSS.
To diagnose
Use the Minify CSS and Minify JavaScript Lighthouse audits to identify resources that need minification.
Repair
If you have limited time, focus on minimizing your JavaScript. Most sites have more JavaScript than CSS, so this will have more impact.
Monitor
Server monitoring tools provide data collection, dashboards, and alerts on server performance. Their use can help prevent and mitigate future server performance problems.
Una configuración de monitoreo debe mantenerse lo más simple factible. La recopilación y alerta excesiva de datos tiene sus costos: cuanto mayor es el scope o la frecuencia de la recopilación de datos, más costoso es recabar y almacenar; una alerta excesiva conduce inevitablemente a páginas ignoradas.
Las alertas deben utilizar métricas que detecten problemas de manera consistente y precisa. El tiempo de respuesta del servidor (latencia) es una métrica que funciona concretamente bien para ello: detecta una amplia variedad de problemas y se correlaciona de forma directa con la experiencia del Username. Las alertas sustentadas en métricas de nivel inferior, como el uso de la CPU, pueden ser un complemento útil, pero detectarán un subconjunto más pequeño de problemas. Al mismo tiempo, las alertas deben basarse en el desempeño observado en la cola (dicho de otra forma, los percentiles 95 o 99), en vez de promedios. Caso contrario, los promedios pueden esconder fácilmente problemas que no impactan a todos los usuarios.
Repair
All major cloud providers offer their own monitoring tools (GCP, AWS, Azure). Further, Netdata is a great free and open source alternative. Regardless of which tool you choose, you must install the tool's monitoring agent on each server that you want to monitor. Once complete, be sure to configure the alerts.
Instructions: