How to bottleneck a server, fix it quickly, improve server performance, and prevent regressions.
Overview
This guide shows you how to repair an overloaded server in 4 steps:
- Browse - Determine the server bottleneck.
- Stabilize - Implement quick fixes to mitigate the impact.
- Upgrade: Increase and optimize server capabilities.
- Monitor - Use automated tools to help prevent future problems.
If you have questions or comments about this guide, or if you want to share your own tips and tricks, please leave a comment on PR # 2479.
Examine
When traffic overloads a server, one or more of the following can become a bottleneck: CPU, network, memory, or disk I / O. Identifying which of these is the bottleneck makes it possible to focus efforts on the most impactful mitigations.
- CPU - CPU usage consistently higher than 80% should be investigated and corrected. Server performance often degrades once CPU usage reaches ~ 80-90%, and becomes more pronounced when usage approaches 100%. CPU utilization to service a single request is negligible, but doing so at the scale encountered during traffic spikes can sometimes overwhelm a server. Offloading the service to another infrastructure, reducing costly operations, and limiting the number of requests will reduce CPU utilization.
- Network - During periods of high traffic, the network performance required to meet user requests may exceed capacity. Some sites, depending on the hosting provider, may also have cumulative data transfer limits. Decreasing the size and amount of data transferred to and from the server will eliminate this bottleneck.
- Memory - When a system does not have enough memory, data must be downloaded to disk for storage. Disk access is considerably slower than memory, and this can slow down an entire application. If memory runs out completely, it may result in Without memory (OOM) errors. Adjusting memory allocation, troubleshooting memory leaks, and upgrading memory can clear this bottleneck.
- Disk I / O - The speed at which data can be read or written from the disk is restricted by the disk itself. If disk I / O is a bottleneck, increasing the amount of data cached can alleviate this problem (at the cost of higher memory utilization). If this doesn't work, your disks may need to be updated.
The techniques in this guide focus on addressing CPU and network bottlenecks. For most sites, the CPU and network will be the most significant bottlenecks during a traffic spike.
In a hurry top on the affected server is a good starting point for investigating bottlenecks. If available, supplement this with historical data from your hosting provider or monitoring tools.
Stabilize
An overloaded server can quickly lead to cascading faults in other parts of the system. Thus, it is essential to stabilize the server before attempting to make more significant changes.
Rate limitation
Rate capping protects the infrastructure by limiting the number of incoming requests. This becomes increasingly important as server performance degrades - as response times increase, users tend to aggressively refresh the page, further increasing server load.
Repair
Although rejecting a request is relatively inexpensive, the best way to protect your server is to handle rate throttling somewhere upstream, for example using a load balancer, reverse proxy, or CDN.
Instructions:
Other readings:
HTTP caching
Look for alternatives to cache content more aggressively. If a resource can be served from an HTTP cache (either the browser cache or a CDN), then it does not need to be requested from the origin server, which reduces the load on the server.
HTTP headers like Cache-Control, Expireand ETag indicate how a resource should be cached through an HTTP cache. Auditing and correcting these headers will improve caching.
Although service employees furthermore they can be used for caching, they use a cache and they are a complement, rather than a replacement, for proper HTTP caching. For this reason, when handling an overloaded server, efforts should be focused on making the most of HTTP caching.
To diagnose
to run Lighthouse and look at the Serve static assets with an efficient cache policy audit to see a list of resources with a short to medium time to live (TTL). For each resource listed, consider whether the TTL should be increased. As a rough guideline:
- Static resources must be cached with a long TTL (1 year).
- Dynamic resources should be cached with a short TTL (3 hours).
Repair
Select the Cache-Control header max-age directive to the appropriate number of seconds.
Instructions:
Note the max-age The directive is just one of many caching directives. There are many other directives and headers that will affect the caching behavior of your application. For a more detailed explanation of the caching strategy, it is strongly recommended that you read HTTP caching.
Elegant degradation
Graceful demotion is the strategy of temporarily decreasing functionality to erase excess load from a system. This concept can be applied in many different ways: by way of example, by publishing a static text page instead of a full-featured application, by disabling search or returning fewer search results, or by disabling certain expensive or nonessential features. Emphasis has to be placed on deleting functionalities that can be safely and easily removed with minimal business impact.
To get better
Use a content delivery network (CDN)
The static asset service can be downloaded from your server to a content delivery network (CDN), thus reducing the load.
The primary function of a CDN is to deliver content to users quickly by providing a large network of servers that are close to the users. Regardless, most CDNs also offer additional features associated with performance, such as compression, load balancing, and media optimization.
Set up a CDN
CDNs benefit from scale, so operating your own CDN rarely makes sense. A basic CDN setup is pretty quick to set up (~ 30 minutes) and involves updating DNS records to point to the CDN.
Get the most out of CDN usage
To diagnose
Identify resources that are not being served from a CDN (but should be) by running WebPageTest. On the results page, click on the box above 'Effective CDN use' to see the list of resources that should be served from a CDN.
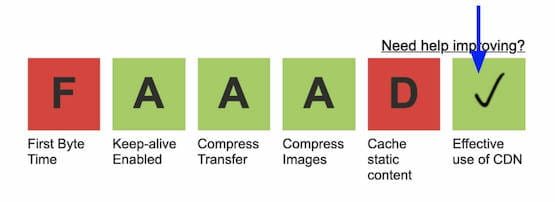
WebPageTest Results
Repair
If the CDN does not cache a resource, verify that the following conditions are met:
Scale computing resources
The decision to scale computing resources must be made carefully. Even though computing resources often need to be scaled, doing so prematurely can lead to unnecessary architectural complexity and financial costs.
To diagnose
A time to first high byte (TTFB) can be a sign that a server is reaching capacity. You can find this information in the Lighthouse Decrease server response times (TTFB) audit.
To investigate further, use a monitoring tool to examine CPU usage. If your current or anticipated CPU usage exceeds 80%, you should consider increasing your servers.
Repair
Adding a load balancer makes it possible to spread traffic across multiple servers. A load balancer faces a group of servers and routes traffic to the appropriate server. Cloud providers offer their own load balancers (GCP, AWS, Azure) or you can configure your own using HAProxy or NGINX. After a load balancer has been deployed, additional servers can be added.
At the same time as load balancing, most cloud providers offer autoscaling (GCP, AWS, Azure). Autoscaling works in conjunction with load balancing: Autoscaling automatically scales compute resources up and down based on demand at a given time. Having said that, autoscaling isn't magic - it takes time for new instances to come online, and it takes significant setup. Due to the additional complexity involved in autoscaling, a simpler load balancer-based configuration should be considered first.
Enable compression
Text-based resources must be compressed via gzip or brotli. Gzip can decrease the transfer size of these resources by approximately 70%.
To diagnose
Use the lighthouse Enable text compression audit to identify the resources to be compressed.
Repair
Enable compression by updating your server settings. Instructions:
Make the most of images and media
Images make up the majority of the file size of most websites; Image optimization can quickly and significantly decrease the size of a site.
To diagnose
Lighthouse has a variety of audits that point to possible image optimizations. Alternatively, another strategy is to use DevTools to identify the largest image files; these images will probably be good candidates for optimization.
Relevant Lighthouse Audits:
Chrome DevTools workflow:
Repair
If you have limited time ...
Focus your time on identifying large and multi-loaded images and manually optimizing them with a tool like Squoosh. Heroic images are generally good candidates for optimization.
Things to pay attention to:
- Size: the images should not be larger than the main thing.
- Compression: Generally speaking, a quality level of 80-85 will have minimal effect on image quality, while it will result in a 30-40% decrease in file size.
- Format: use JPEG for photos instead of PNG; use MP4 for animated content instead of GIF.
If you have more time ...
Consider setting up an image CDN if images make up a substantial part of your site. Image CDNs are designed to serve and take full advantage of images and will download the image service from the origin server. Setting up an Image CDN is straightforward, but you need to update the existing Image URLs to point to the Image CDN.
Other readings:
Minify JS and CSS
Minification removes unnecessary JavaScript and CSS characters.
To diagnose
Use the Minify CSS and Minify JavaScript Lighthouse audits to identify resources that need minification.
Repair
If you have limited time, focus on minimizing your JavaScript. Most sites have more JavaScript than CSS, so this will have more impact.
Monitor
Server monitoring tools provide data collection, dashboards, and alerts on server performance. Their use can help prevent and mitigate future server performance problems.
A monitoring setup should be kept as simple as possible. Excessive data collection and alerting has its costs: the greater the scope or frequency of data collection, the more expensive it is to collect and store; excessive alertness inevitably leads to ignored pages.
Alerts must use metrics that consistently and accurately detect problems. Server response time (latency) is a metric that works particularly well for this: it detects a wide variety of problems and is directly correlated to user experience. Alerts based on lower-level metrics, such as CPU usage, can be a useful adjunct, but will detect a smaller subset of issues. At the same time, alerts should be based on observed performance in the queue (in other words, the 95th or 99th percentiles), rather than averages. Otherwise, averages can easily hide problems that do not impact all users.
Repair
All major cloud providers offer their own monitoring tools (GCP, AWS, Azure). Further, Netdata is a great free and open source alternative. Regardless of which tool you choose, you must install the tool's monitoring agent on each server that you want to monitor. Once complete, be sure to configure the alerts.
Instructions: