The robots.txt file is a document that establishes which parts of a domain can be analyzed by search engine crawlers and provides a link to the XML-sitemap.
Structure
The call "Robots Exclusion Standard Protocol", Standard Protocol for Robots Exclusions, was first published in 1994. This protocol defines that search engine crawlers must find and read the file named "Robots.txt" before starting indexing. That is why it should be placed in the root directory of the domain. In spite of everything, we must remember that not all trackers follow this same rule and therefore, the "Robots.txt" they do not promise the 100% access and privacy protection. Some search engines still index blocked pages and even show those with no description in the SERPs. This is particularly the case with websites that contain too many links. Regardless, the major search engines like Google, Yahoo and Bing yes they conform to the protocol rules "Robots.txt".
Creation and control of the "robots.txt"
It is simple to create a "Robots.txt" with the help of a text editor. At the same time, you can find free tools on the internet that offer detailed information about how to generate a file. "Robots.txt" or that they even automatically create it for you. Each file contains 2 blocks. In the first, it is specified for which users the instructions are valid. In the second block the instructions are written, called "Disallow", with the list of pages to be excluded. It is recommended to check carefully that the file has been written correctly before downloading it to the directory since, with basically a tiny syntax error, you can misinterpret the instructions and index pages that, in theory, should not appear in the search results . To check if the file "Robots.txt" works correctly you can use Google's webmaster tool and perform an analysis on „status“ -> „blocked URLs“.
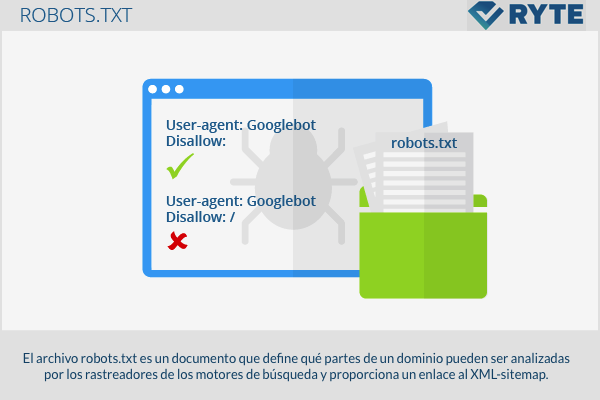
Pages exclusion
The simplest structure of a file robots.txt appears as follows:
User-agent: Googlebot Disallow:
This code allows Googlebot to analyze all pages. The opposite, such as the complete ban of the web portal, is written as follows: '
User-agent: Googlebot Disallow:
In the "User-agent" line the user writes who it is addressed to. The following terms can be used:
- Googlebot (Google search engine)
- Googlebot-Image (Google-image search)
- Adsbot-Google (Google AdWords)
- Slurp (Yahoo)
- bingbot (Bing)
If the order is addressed to different users, each robot will have its own line. In mindshape.de you will be able to find a summary of the most common orders and parameters for creating a robots.txt. Furthermore, a link to an XML-Sitemap can be added as follows:
Sitemap: http://www.domain.de/sitemap.xm
Example
# robots.txt for http://www.example.com/ User-agent: UniversalRobot / 1.0 User-agent: my-robot Disallow: / sources / dtd / User-agent: * Disallow: / nonsense / Disallow: / temp / Disallow: /newsticker.shtml
Relevance for SEO
The use of the protocol robots.txt influences crawlers' access to the web portal. There are two different commands: "Allow" and "disallow". It is very important to use this protocol correctly since if the webmaster blocks by mistake - by means of the "disallow" command - important files and contents of the web portal, the crawlers will not be able to read or index it. Regardless, if used correctly webmasters are able to inform crawlers on how to review the internal structure of their web portal.
Web links
- Information about robots.txt files support.google.com
- Robots.txt file: what it is, what it is for and how to create it Blog ignaciosantiago.com



