A crawler, commonly known as tracker, is a program that analyzes documents on websites. Search engines have very powerful crawlers that navigate and analyze websites and create a database with the information collected. The term crawler comes from the first internet search engine, the Web Crawler. It is also known as crawler spider or robot.
Functioning
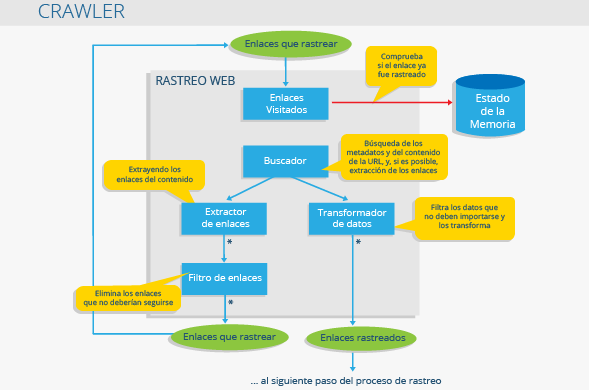
In principle a crawler it is like a librarian. It searches for information on the web portal, categorizes it and indexes it before it is analyzed.
The operations of this program must be established before the crawler start going through a web portal. The crawler processes these orders automatically and, thus, the type of information obtained by the crawler it depends exclusively on the rules that have been established for it.
Use
The main objective of crawler is to create a database. In this way, crawlers They are the work tools that search engines use to extract the information they need to examine websites and establish their positioning in the SERPs. The Focused Crawler they concentrate, for example, on reviewing websites and looking for specific and relevant information, depending on the orders that have been placed on them.
Some of the apps of the crawlers are:
- Price comparison on product portals
- In the field of "Data mining" a crawler you can, for example, organize company emails and postal codes
- Collection of data related to website visits and information on external links, Backlink
Crawler vs. Scraper
A crawler it is basically a data collector. Nonetheless, scrapping is a Black Hat SEO technique that aims to copy data, such as content, from a web portal for use on other websites.
Block a crawler
Who does not want certain crawlers scan your web portal can block them with the file robots.txt. This does not prevent the content from being indexed by search engines, for this the Noindex tags or Rel = Canonical tag should be used.
Web links
- Google trackers support.google.com
- How precisely does Google work? Blog ignaciosantiago.com





