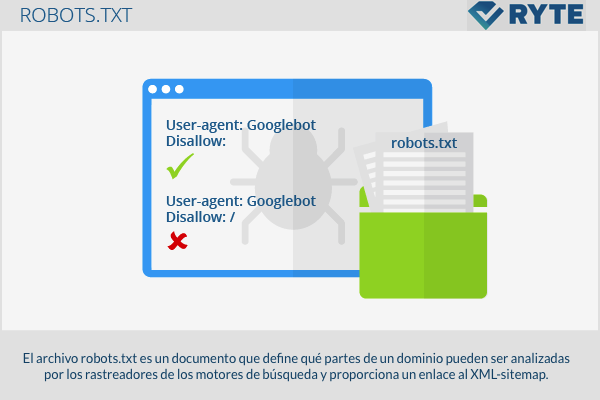
El archivo robots.txt es un documento que establece qué partes de un dominio pueden ser analizadas por los rastreadores de los motores de búsqueda y proporciona un link al XML-sitemap.
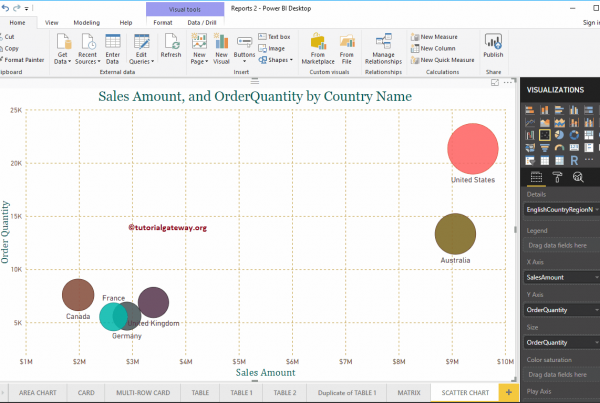
Estructura
El llamado “Robots Exclusion Standard Protocol“, Protocolo Estándar de Exclusiones Robots, se publicó por primera vez en 1994. Este protocolo define que los rastreadores de los motores de búsqueda deben buscar y leer el archivo llamado “robots.txt“ antes de comenzar con la indexación. Es por ello que se debe colocar en el directorio raíz del dominio. A pesar de todo, debemos recordar que no todos los rastreadores siguen esta misma regla y por ende, los “robots.txt“ no prometen al 100% protección de acceso y privacidad. Algunos motores de búsqueda aún indexan las páginas bloqueadas y muestran inclusive aquellas sin descripción en los SERPs. Esto sucede concretamente con sitios web que contienen demasiados enlaces. A pesar de todo, los motores de búsqueda más importantes como Google, Yahoo y Bing sí que se ajustan a las normas del protocolo “robots.txt“.
Creación y control del “robots.txt“
Es simple crear un “robots.txt“ con la ayuda de un editor de textos. Al mismo tiempo, puedes hallar herramientas gratuitas en internet que ofrecen información detallada acerca de cómo generar un archivo “robots.txt“ o que, inclusive, te lo crean automáticamente. Cada archivo contiene 2 bloques. En el primero, se especifica para qué usuarios son válidas las instrucciones. En el segundo bloque se escriben las instrucciones, llamadas “disallow“, con el listado de las páginas que deben excluirse. Se recomienda comprobar con atención que el archivo se haya escrito correctamente antes de descargarlo en el directorio dado que, con básicamente un minúsculo error de sintaxis, se pueden malinterpretar las instrucciones e indexar páginas que, en teoría, no deberían salir en los resultados de búsqueda. Para verificar si el archivo “robots.txt“ funciona correctamente se puede usar la herramienta webmaster de Google y realizar un análisis en „status“ -> „blocked URLs“.
Exclusión de páginas
La estructura más simple de un archivo robots.txt aparece del siguiente modo:
User-agent: Googlebot Disallow:
Este código permite que Googlebot analice todas las páginas. Lo contrario, como por ejemplo la prohibición completa del portal web, se escribe del siguiente modo: ‘
User-agent: Googlebot Disallow:
En la línea del “User-agent“ el usuario escribe para quién va dirigido. Pueden utilizarse los siguientes términos:
- Googlebot (Google search engine)
- Googlebot-Image (Google-image search)
- Adsbot-Google (Google AdWords)
- Slurp (Yahoo)
- bingbot (Bing)
Si la orden va dirigida a distintos usuarios cada robot tendrá su línea propia. En mindshape.de vas a poder hallar un resumen de las órdenes y parámetros más comunes para la creación de un robots.txt. Además se puede añadir un link a un XML-Sitemap del siguiente modo:
Sitemap: http://www.domain.de/sitemap.xm
Ejemplo
# robots.txt for http://www.example.com/ User-agent: UniversalRobot/1.0 User-agent: my-robot Disallow: /sources/dtd/ User-agent: * Disallow: /nonsense/ Disallow: /temp/ Disallow: /newsticker.shtml
Relevancia para el SEO
El uso del protocolo robots.txt influye en el acceso de los rastreadores al portal web. Hay dos comandos distintos: «allow» y «disallow». Es muy importante usar correctamente este protocolo dado que si el webmaster bloquea por error – mediante de la orden «disallow» – archivos y contenidos importantes del portal web los rastreadores no serán capaces de leerlo ni indexarlo. A pesar de todo, si se usa correctamente los webmasters son capaces de informar a los rastreadores de cómo repasar la estructura interna de su portal web.
Enlaces web
- Información sobre los archivos robots.txt support.google.com
- Archivo robots.txt: Qué es, para qué sirve y cómo crearlo Blog ignaciosantiago.com