

Permitir que los trabajadores del servicio le digan a los navegadores qué páginas funcionan sin conexión
Actualizado
¿Qué es la API de indexación de contenido?
Usando un aplicación web progresiva significa tener acceso a la información que le interesa a la gente (imágenes, videos, artículos y más) independientemente del estado actual de su conexión de red. Tecnologías como trabajadores de servicio, el API de almacenamiento en cachéy IndexedDB
proporcionarle los componentes básicos para almacenar y entregar datos cuando las personas interactúan directamente con una PWA. Pero construir una PWA de alta calidad, primero sin conexión, es solo una parte de la historia. Si las personas no se dan cuenta de que el contenido de una aplicación web está disponible mientras están desconectadas, no aprovecharán al máximo el trabajo que dedicó a implementar esa funcionalidad.
Esto es un descubrimiento problema; ¿Cómo puede su PWA hacer que los usuarios conozcan su contenido sin conexión para que puedan descubrir y ver lo que está disponible? La API de indexación de contenido es una solución a este problema. La parte de esta solución orientada al desarrollador es una extensión para los trabajadores del servicio, que permite a los desarrolladores agregar URL y metadatos de páginas con capacidad sin conexión a un índice local mantenido por el navegador. Esa mejora está disponible en Chrome 84 y versiones posteriores.
Una vez que el índice se completa con el contenido de su PWA, así como cualquier otro PWA instalado, el navegador lo mostrará como se muestra a continuación.
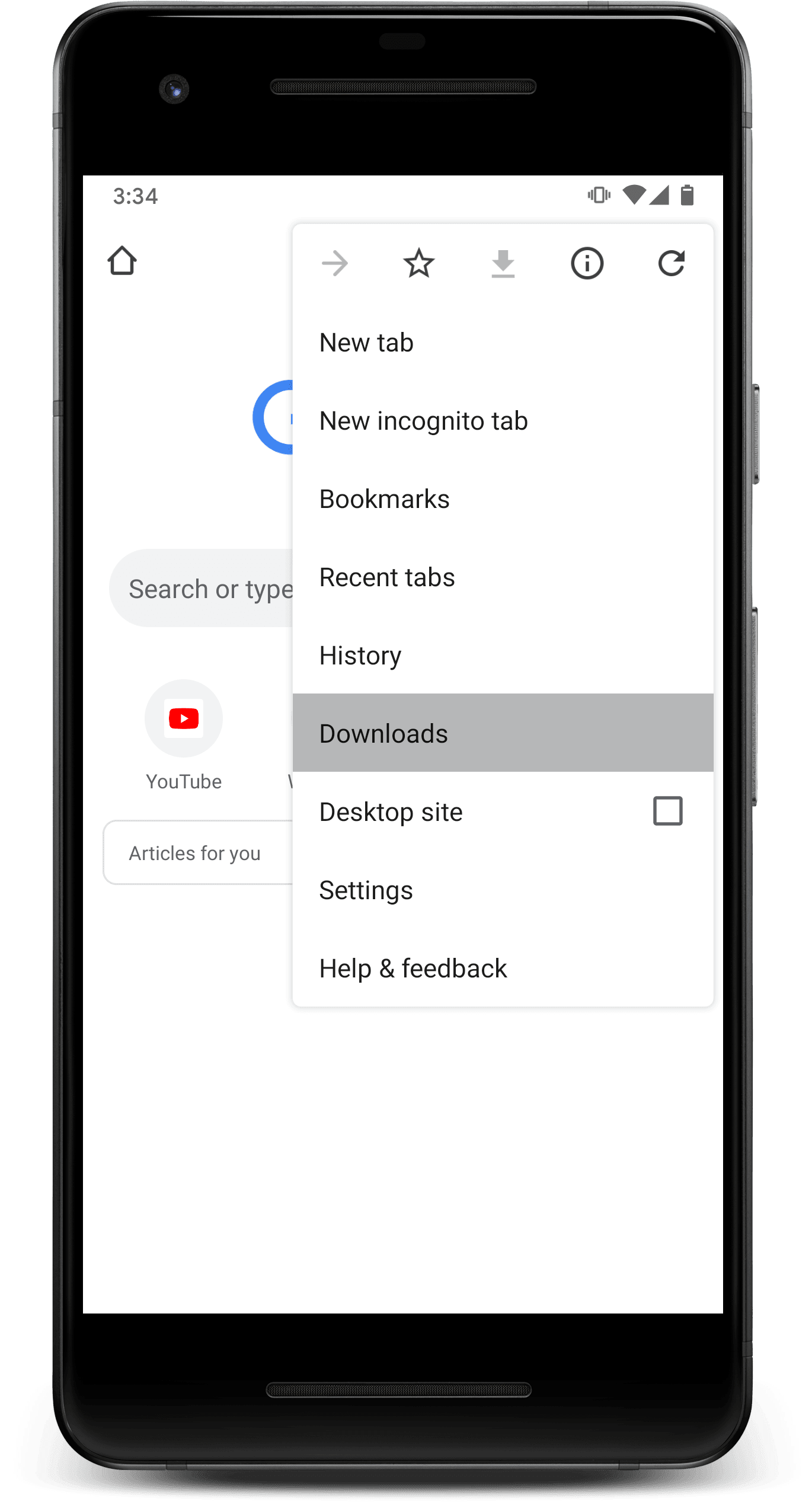
Primero, seleccione el Descargas elemento de menú en la página de nueva pestaña de Chrome.
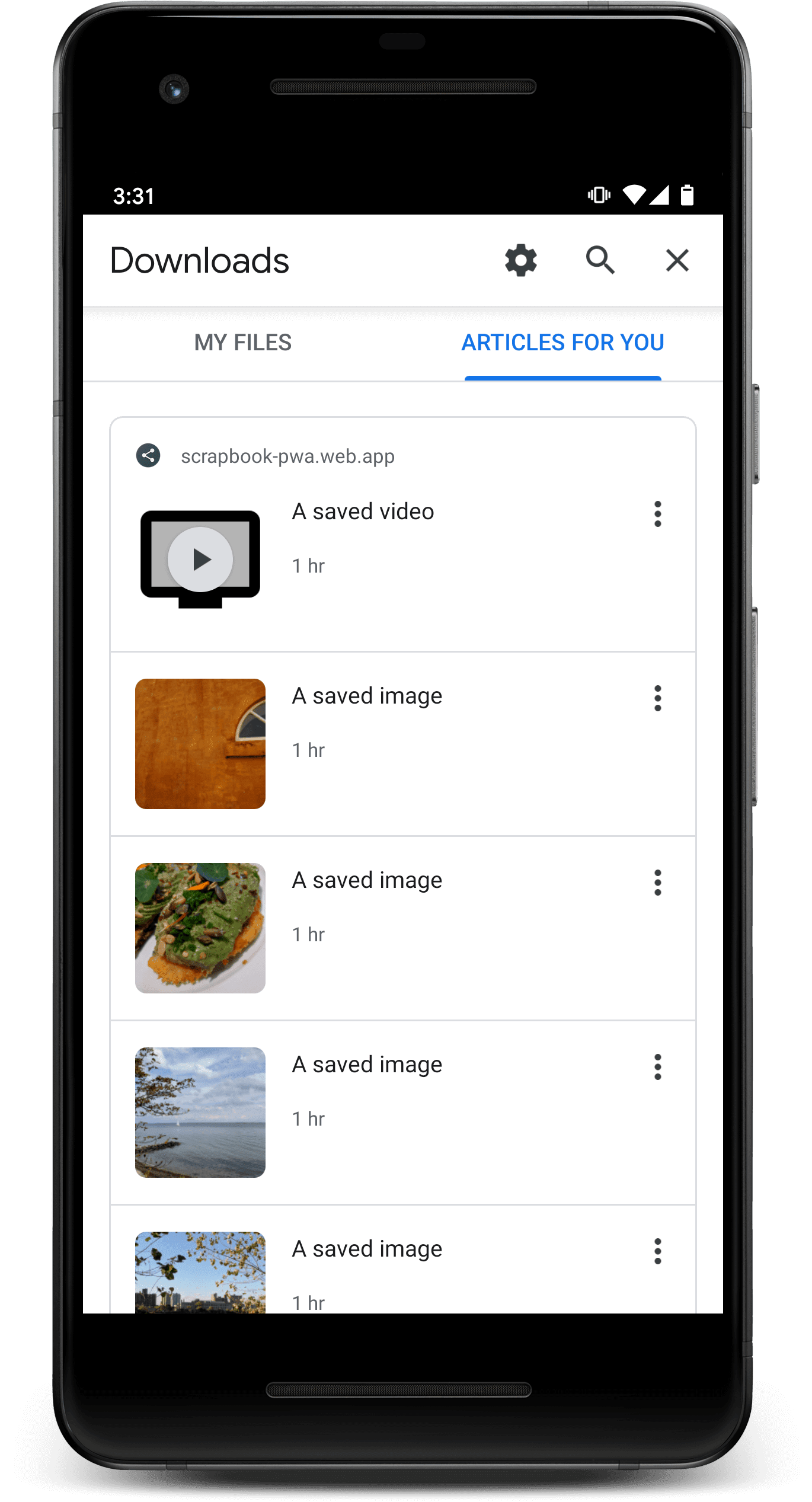
Los medios y artículos que se han agregado al índice se mostrarán en el
Artículos para ti sección.
Además, Chrome puede recomendar contenido de forma proactiva cuando detecta que un usuario está desconectado.
La API de indexación de contenido no es una forma alternativa de almacenar contenido en caché. Es una forma de proporcionar metadatos sobre páginas que su trabajador del servicio ya almacena en caché, de modo que el navegador pueda mostrar esas páginas cuando es probable que la gente quiera verlas. La API de indexación de contenido ayuda con descubrimiento de páginas en caché.
La API de indexación de contenido no es un índice de búsqueda. Si bien puede obtener una lista de todas las entradas indexadas, no hay forma de consultar directamente los metadatos indexados.
Míralo en acción
La mejor manera de familiarizarse con la API de indexación de contenido es probar una aplicación de muestra.
- Asegúrese de estar utilizando un navegador y una plataforma compatibles. Actualmente, eso se limita a Chrome 84 o posterior en Android. Ir
chrome://versionpara ver qué versión de Chrome está ejecutando. - Visitar https://contentindex.dev
- Haga clic en el
+junto a uno o más de los elementos de la lista. - (Opcional) Desactive la conexión de datos móviles y Wi-Fi de su dispositivo, o active el modo avión para simular que su navegador está fuera de línea.
- Escoger Descargas en el menú de Chrome y cambie al Artículos para ti lengüeta.
- Navegue por el contenido que guardó anteriormente.
Puedes ver la fuente de la aplicación de muestra en GitHub.
Otra aplicación de muestra, una Álbum de recortes PWA, ilustra el uso de la API de indexación de contenido con la API de destino de recurso compartido web. los el código demuestra una técnica
para mantener la API de indexación de contenido sincronizada con los elementos almacenados por una aplicación web utilizando el API de almacenamiento en caché.
Usando la API
Para utilizar la API, su aplicación debe tener un trabajador de servicio y URL navegables sin conexión. Si su aplicación web no tiene actualmente un trabajador de servicio, el Bibliotecas de Workbox puede simplificar la creación de uno.
¿Qué tipo de URL se pueden indexar como sin conexión?
La API admite la indexación de URL correspondientes a documentos HTML. Una URL para un archivo de medios en caché, por ejemplo, no se puede indexar directamente. En su lugar, debe proporcionar una URL para una página que muestre medios y que funcione sin conexión.
Un patrón recomendado es crear una página HTML de «visor» que pueda aceptar la URL del medio subyacente como parámetro de consulta y luego mostrar el contenido del archivo, potencialmente con controles adicionales o contenido en la página.
Las aplicaciones web solo pueden agregar URL al índice de contenido que se encuentran bajo la
alcance
del trabajador del servicio actual. En otras palabras, una aplicación web no puede agregar una URL que pertenezca a un dominio completamente diferente en el índice de contenido.
Visión general
La API de indexación de contenido admite tres operaciones: agregar, enumerar y eliminar metadatos. Estos métodos están expuestos a partir de una nueva propiedad, index, que se ha agregado a la
ServiceWorkerRegistration
interfaz.
El primer paso para indexar contenido es obtener una referencia a la
ServiceWorkerRegistration. Utilizando navigator.serviceWorker.ready es la forma más sencilla:
const registration = await navigator.serviceWorker.ready;
if ('index' in registration) {
}
Si realiza llamadas a la API de indexación de contenido desde dentro de un trabajador del servicio, en lugar de dentro de una página web, puede consultar la ServiceWorkerRegistration
directamente a través de registration. Va a ya está definido
como parte de la ServiceWorkerGlobalScope.
Añadiendo al índice
Utilizar el add() método para indexar URL y sus metadatos asociados. Depende de usted elegir cuándo se agregan los elementos al índice. Es posible que desee agregar al índice en respuesta a una entrada, como hacer clic en el botón «guardar sin conexión». O puede agregar elementos automáticamente cada vez que los datos almacenados en caché se actualizan mediante un mecanismo como sincronización periódica en segundo plano.
await registration.index.add({
id: 'article-123',
url: '/articles/123',
launchUrl: '/articles/123',
title: 'Article title',
description: 'Amazing article about things!',
icons: [{
src: '/img/article-123.png',
sizes: '64x64',
type: 'image/png',
}],
category: 'article',
});
Agregar una entrada solo afecta el índice de contenido; no agrega nada al
cache.
Caso de borde: llamada add() de window contexto si sus iconos se basan en un fetch manipulador
Cuando usted llama add(), Chrome solicitará la URL de cada ícono para asegurarse de que tenga una copia del ícono para usar al mostrar una lista de contenido indexado.
-
Si llamas
add()desde elwindowcontexto (en otras palabras, desde su página web), esta solicitud activará unafetchevento en su trabajador de servicio. -
Si llamas
add()dentro de su trabajador de servicio (tal vez dentro de otro controlador de eventos), la solicitud no desencadenar el trabajador del serviciofetchmanipulador. Los iconos se recuperarán directamente, sin la participación de ningún trabajador del servicio. Tenga esto en cuenta si sus iconos dependen de sufetchhandler, quizás porque solo existen en la caché local y no en la red. Si lo hacen, asegúrese de llamar soloadd()desde elwindowcontexto.
Listado del contenido del índice
los getAll() El método devuelve una promesa de una lista iterable de entradas indexadas y sus metadatos. Las entradas devueltas contendrán todos los datos guardados con
add().
const entries = await registration.index.getAll();
for (const entry of entries) {
}Eliminar elementos del índice
Para eliminar un elemento del índice, llame delete() con el id del artículo a eliminar:
await registration.index.delete('article-123');Vocación delete() solo afecta al índice. No elimina nada de la
cache.
Advertencia:
Una vez indexadas, las entradas no caducan automáticamente. Depende de usted presentar una interfaz en su aplicación web para borrar las entradas o eliminar periódicamente las entradas más antiguas que sabe que ya no deberían estar disponibles sin conexión.
Manejo de un evento de eliminación de usuario
Cuando el navegador muestra el contenido indexado, puede incluir su propia interfaz de usuario con un Eliminar elemento del menú, dando a las personas la oportunidad de indicar que han terminado de ver contenido indexado previamente. Así es como se ve la interfaz de eliminación en Chrome 80:
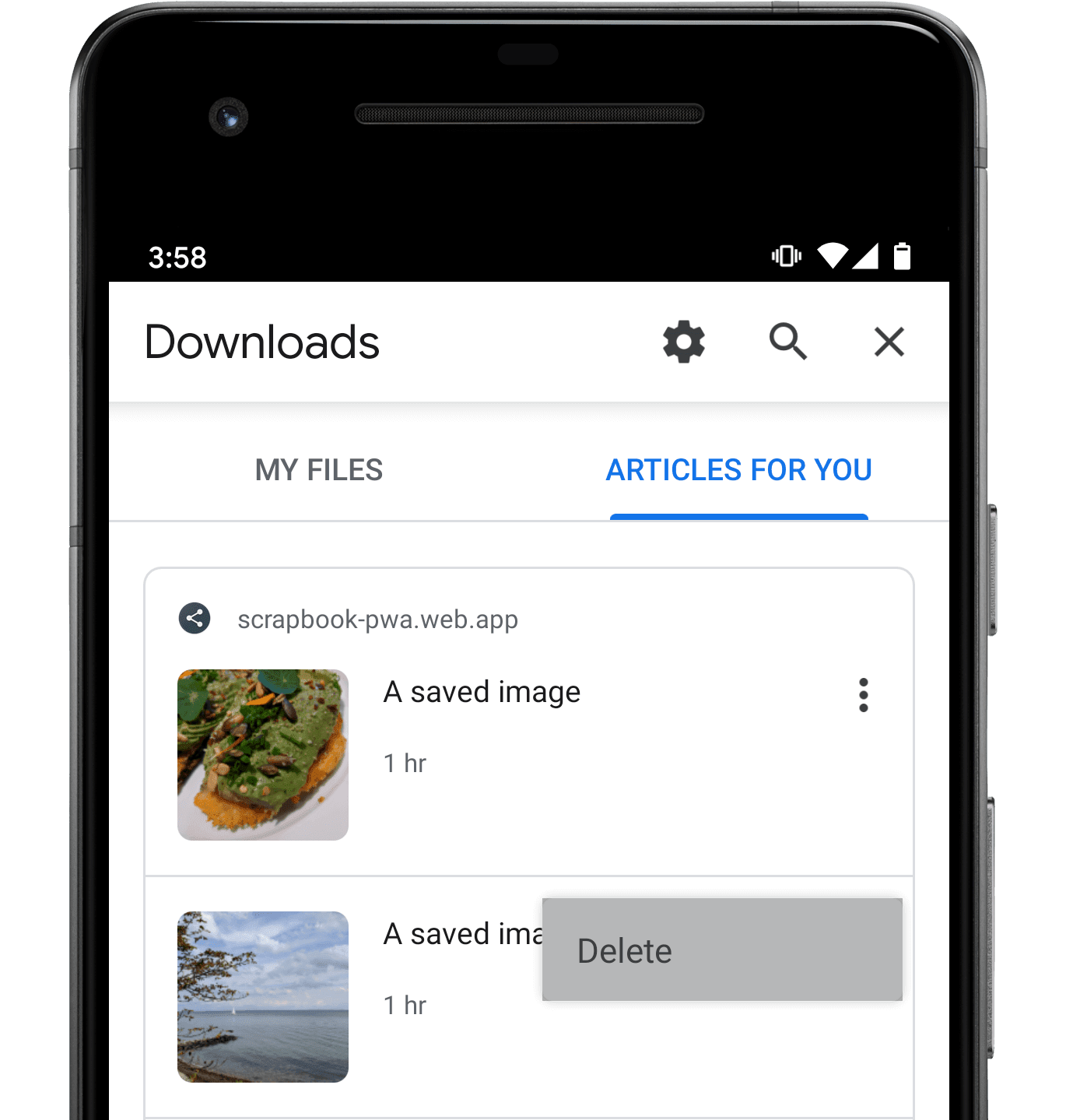
Cuando alguien selecciona ese elemento del menú, el trabajador del servicio de su aplicación web recibirá un contentdelete evento. Si bien el manejo de este evento es opcional, le brinda a su trabajador de servicio la oportunidad de «limpiar» el contenido, como archivos de medios almacenados en caché local, que alguien ha indicado que ha terminado.
No necesitas llamar registration.index.delete() dentro de tu
contentdelete manipulador; si el evento se ha disparado, el navegador ya ha realizado la eliminación del índice correspondiente.
self.addEventListener('contentdelete', (event) => {
});los contentdelete El evento solo se activa cuando la eliminación ocurre debido a la interacción con la interfaz de usuario integrada del navegador. Es no despedido cuando
registration.index.delete() se llama. Si su aplicación web activa la eliminación del índice utilizando ese método de API, también debería limpiar contenido en caché al mismo tiempo.
Comentarios sobre el diseño de la API
¿Hay algo en la API que es incómodo o no funciona como se esperaba? ¿O faltan piezas que necesitas para implementar tu idea?
Presentar un problema en el Repositorio de GitHub explicativo de la API de indexación de contenidoo agregue sus pensamientos a un problema existente.
¿Problema con la implementación?
¿Encontraste un error con la implementación de Chrome?
Presentar un error en https://new.crbug.com. Incluya todos los detalles que pueda, instrucciones sencillas para reproducir y configurar Componentes
a Blink>ContentIndexing.
¿Planea utilizar la API?
¿Planea utilizar la API de indexación de contenido en su aplicación web? Su soporte público ayuda a Chrome a priorizar funciones y muestra a otros proveedores de navegadores lo importante que es brindarles soporte.
- Enviar un tweet a @Cromodev con
#ContentIndexingAPIy detalles sobre dónde y cómo lo está usando.
¿Cuáles son algunas implicaciones de seguridad y privacidad de la indexación de contenido?
Revisa las respuestas
proporcionado en respuesta a los W3C Cuestionario de seguridad y privacidad. Si tiene más preguntas, inicie un debate a través del Repositorio de GitHub.
Imagen de héroe de Maksym Kaharlytskyi en Unsplash.




