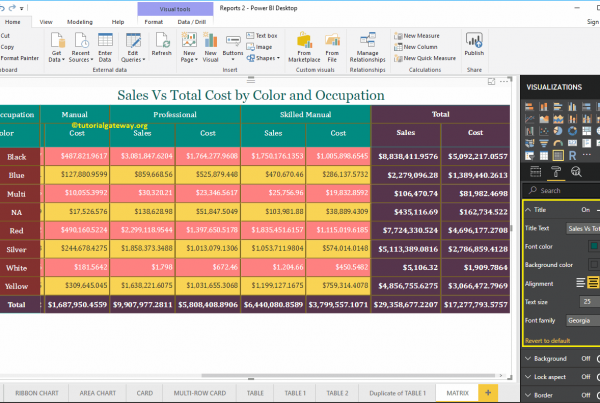
Das robots.txt Datei ist ein Dokument, das festlegt, welche Teile einer Domain von Suchmaschinen-Crawlern analysiert werden können, und einen Link zu XML-Sitemap.
Struktur
Der Anruf "Robots Exclusion Standard Protocol", Standardprotokoll für RoboterausschlüsseDieses Protokoll definiert, dass Suchmaschinen-Crawler die genannte Datei finden und lesen müssen "Robots.txt" bevor Sie mit der Indizierung beginnen. Aus diesem Grund sollte es im Stammverzeichnis der Domäne abgelegt werden. Trotz allem müssen wir uns daran erinnern, dass nicht alle Tracker der gleichen Regel folgen und daher die "Robots.txt" Sie versprechen keinen 100%-Zugang und keinen Datenschutz. Einige Suchmaschinen indizieren weiterhin blockierte Seiten und zeigen sogar solche ohne Beschreibung in den SERPs an. Dies ist insbesondere bei Websites der Fall, die zu viele Links enthalten. Unabhängig davon mögen die großen Suchmaschinen Google, Yahoo y Bing Ja, sie entsprechen den Protokollregeln "Robots.txt".
Erstellung und Kontrolle der "robots.txt"
Es ist einfach, eine zu erstellen "Robots.txt" mit Hilfe eines Texteditors. Gleichzeitig finden Sie im Internet kostenlose Tools, die detaillierte Informationen zum Generieren einer Datei bieten. "Robots.txt" oder dass sie es sogar automatisch für Sie erstellen. Jede Datei enthält 2 Blöcke. Im ersten wird angegeben, für welche Benutzer die Anweisungen gültig sind. Im zweiten Block werden die Anweisungen geschrieben, aufgerufen "Nicht zulassen", mit der Liste der auszuschließenden Seiten. Es wird empfohlen, sorgfältig zu überprüfen, ob die Datei korrekt geschrieben wurde, bevor Sie sie in das Verzeichnis herunterladen, da Sie mit einem winzigen Syntaxfehler die Anweisungen und Indexseiten falsch interpretieren können, die theoretisch nicht in den Suchergebnissen erscheinen sollten. Um zu überprüfen, ob die Datei "Robots.txt" funktioniert einwandfrei Sie können das Webmaster-Tool von Google verwenden und eine Analyse zu „Status“ -> „Blockierte URLs“ durchführen.
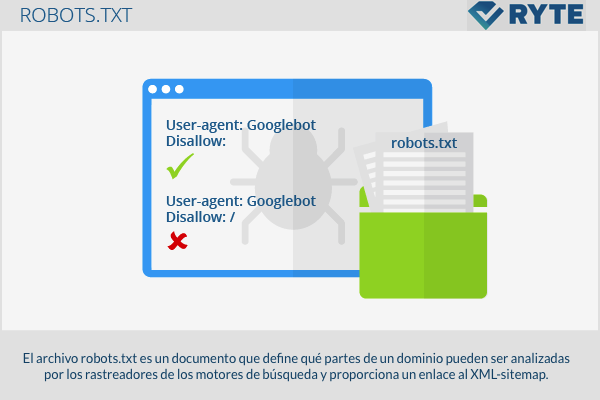
Seitenausschluss
Die einfachste Struktur einer Datei robots.txt erscheint wie folgt:
User-Agent: Googlebot Disallow:
Mit diesem Code kann Googlebot alle Seiten analysieren. Das Gegenteil, wie das vollständige Verbot des Webportals, lautet wie folgt: '
User-Agent: Googlebot Disallow:
In die Zeile "User-Agent" schreibt der Benutzer, an wen er adressiert ist. Die folgenden Begriffe können verwendet werden:
- Googlebot (Google-Suchmaschine)
- Googlebot-Image (Google-Bildsuche)
- Adsbot-Google (Google AdWords)
- Slurp (Yahoo)
- Bingbot (Bing)
Wenn die Bestellung an verschiedene Benutzer gerichtet ist, hat jeder Roboter eine eigene Linie. Im mindshape.de Sie finden eine Zusammenfassung der häufigsten Aufträge und Parameter zum Erstellen eines robots.txt. Darüber hinaus kann ein Link zu einer XML-Sitemap wie folgt hinzugefügt werden:
Sitemap: http://www.domain.de/sitemap.xm
Beispiel
# robots.txt für http://www.example.com/ Benutzeragent: UniversalRobot / 1.0 Benutzeragent: my-robot Nicht zulassen: / sources / dtd / Benutzeragent: * Nicht zulassen: / nonsense / Nicht zulassen: / temp / Nicht zulassen: /newsticker.shtml
Relevanz für SEO
Die Verwendung des Protokolls robots.txt beeinflusst den Zugriff von Crawlern auf das Webportal. Es gibt zwei verschiedene Befehle: "Zulassen" und "Nicht zulassen". Es ist sehr wichtig, dieses Protokoll korrekt zu verwenden, da die Crawler es nicht lesen oder indizieren können, wenn der Webmaster versehentlich - mithilfe des Befehls "disallow" - wichtige Dateien und Inhalte des Webportals blockiert. Unabhängig davon können Webmaster bei korrekter Verwendung Crawler darüber informieren, wie sie die interne Struktur ihres Webportals überprüfen können.
Web-Links
- Informationen zu robots.txt-Dateien support.google.com
- Robots.txt-Datei: Was es ist, wofür es ist und wie man es erstellt Blog ignaciosantiago.com