UNE robot d'exploration, mieux connu sous le nom de traqueur, est un programme qui analyse des documents sur des sites Web. Les moteurs de recherche ont des robots d'exploration très puissants qui naviguent et analysent les sites Web et créent une base de données avec les informations collectées. Le terme robot d'exploration provient du premier moteur de recherche Internet, le Explorateur Web. Il est également connu sous le nom chenille, araignée ou robot.
Fonctionnement
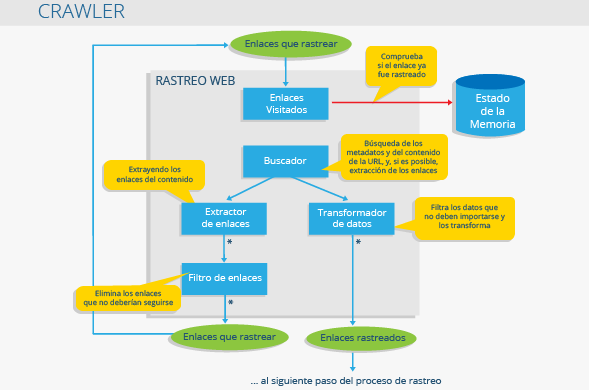
En principe un robot d'exploration c'est comme un bibliothécaire. Il recherche des informations sur le portail web, les catégorise et les indexe avant qu'elles ne soient analysées.
Les opérations de ce programme doivent être établies avant la robot d'exploration commencer à passer par un portail Web. le robot d'exploration traite automatiquement ces commandes et, par conséquent, le type d'informations obtenues par le robot d'exploration elle dépend exclusivement des règles qui ont été établies.
Utiliser
L'objectif principal de robot d'exploration est de créer une base de données. De cette façon, robots d'exploration sont les outils de travail que les moteurs de recherche utilisent pour extraire les informations dont ils ont besoin pour examiner les sites Web et établir leur positionnement dans les SERP. Les Crawler focalisé ils se concentrent, par exemple, sur l'examen des sites Web et la recherche d'informations spécifiques et pertinentes, en fonction des commandes qui leur ont été passées.
Certaines des applications du robots d'exploration ils sont:
- Comparaison des prix sur les portails de produits
- Dans le domaine de « Exploration de données » une robot d'exploration vous pouvez, par exemple, organiser les e-mails et les codes postaux des entreprises
- Collecte de données liées aux visites du site et informations sur les liens externes, Backlink
Crawler vs. Grattoir
UNE robot d'exploration il s'agit essentiellement d'un collecteur de données. Malgré tout, mise au rebut est une technique de référencement Black Hat qui vise à copier des données, telles que du contenu, à partir d'un portail Web pour les utiliser sur d'autres sites Web.
Bloquer un robot d'exploration
Qui ne veut pas certain robots d'exploration scannez votre portail web peut les bloquer avec le fichier robots.txt. Cela n'empêche pas le contenu d'être indexé par les moteurs de recherche, pour cela il faut utiliser les balises Noindex ou Rel = Canonical.
liens web
- Traqueurs Google support.google.com
- Avec quelle précision Google fonctionne-t-il ? Blog ignaciosantiago.com





