

Wenn Sie neu in der Suchmaschinenoptimierung (SEO) sind oder zum ersten Mal mit begegnen Schreiender Frosch , Dieser Beitrag ist für Sie!
Beim Versuch, ein Gleichgewicht zwischen dem Erlernen neuer SEO-Konzepte zu finden als Teilzeitpraktikant und machen Sie sich mit den Tools vertraut, die wir täglich verwenden, Bekanntlich hatten wir weniger Zeit, um mit den Konzepten zu interagieren .
Mein erster Crawl als Praktikant war für eine Site mit mehr als Hunderttausenden von URLs und ich stieß auf eine Handvoll Probleme, aus denen ich lernen musste. Wenn Sie anfangen, an SEO zu arbeiten, finden Sie leistungsstarke Tools, mit denen Sie wertvolle Daten finden können. Es ist wichtig, diese Tools so effizient wie möglich verwenden und navigieren zu können.
Bei R Digital Marketing heißt das häufig verwendete Tool Screaming Frog, ein Website-Crawler, der URLs verfolgt und wertvolle Daten zurückgibt, die wir für die Prüfung von Websites und technischen SEOs analysieren können.
In diesem Blog erfahren Sie, wie Sie Ihr Gerät für Screaming Frog einrichten und welche Einstellungen vorgenommen werden, um eine Site zu crawlen und Ihren Crawl auszuführen.
Einrichten Ihres Geräts
Wenn Sie mit dem Crawlen von Websites beginnen, werden Sie feststellen, dass einige Websites größer als andere sind und mehr Speicher von Ihrem System benötigen, um die gefundenen Daten von Screaming Frog zu speichern und zu verarbeiten. Bevor Sie mit dem Crawlen von Websites beginnen, sollten Sie Screaming Frog mehr RAM von Ihrem System zuweisen, um mehr Geschwindigkeit und Flexibilität für alle zukünftigen Crawls zu ermöglichen. Dies ist erforderlich, damit Websites mit mehr als 150.000 URLs gecrawlt werden können.
Konfiguration> System> Speicher
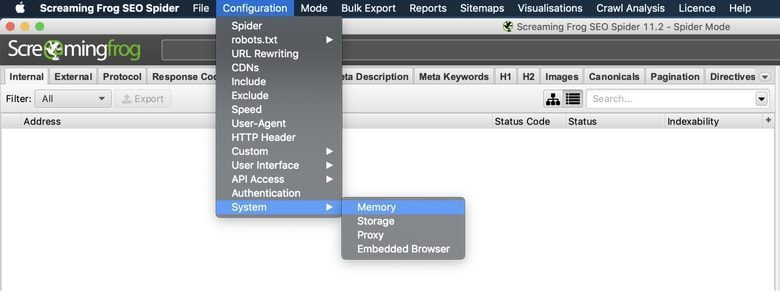
Die Standardeinstellung für 32-Bit-Computer ist 1 GB RAM und 2 GB RAM für 64-Bit-Computer. Ich empfehle die Verwendung von 8 GB, wodurch Screaming Frog bis zu 5 Millionen URLs crawlen kann. Screaming Frog empfiehlt, 2 GB weniger als Ihren gesamten RAM zu verwenden. Seien Sie jedoch vorsichtig, wenn Sie den gesamten RAM reservieren, kann es zu einem Absturz Ihres Systems kommen.
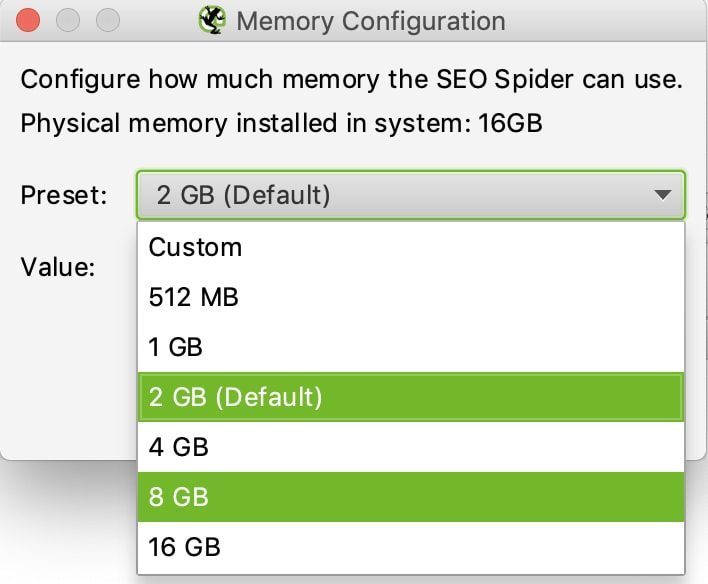
Wenn Sie Screaming Frog mehr RAM zugewiesen haben, müssen Sie Ihre Software neu starten, damit die Änderungen wirksam werden.
Konfigurationen
Sobald Sie mit dem Crawlen von Websites beginnen, müssen Sie Ihre Einstellungen entsprechend anpassen, um sicherzustellen, dass Screaming Frog so effizient wie möglich crawlt. Hier zeige ich Ihnen einige Grundeinstellungen, die ich gerne benutze.
Einstellungen> Spider> Basic
Dies sind die Standardeinstellungen, die Screaming Frog für jeden Crawl hat. Es ist eine gute Angewohnheit, Ihre spezifischen Einstellungen für den Crawl festzulegen, den Sie ausführen möchten, und hier Anpassungen vorzunehmen.
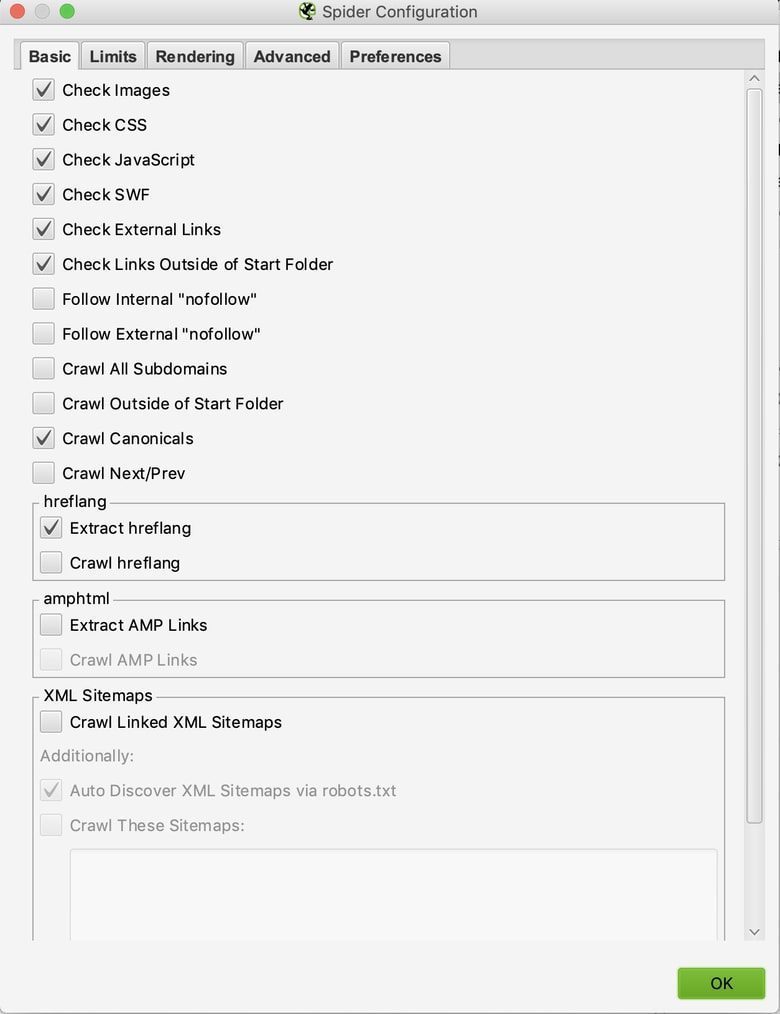
Dies sind die Grundeinstellungen, die ich hier bei R Marketing verwende, um meine technischen Audits durchzuführen:
- Folgen Sie " nicht folgen ”Intern : ermöglicht es uns, interne Links mit "nofollow-Attributen" zu verfolgen, um zu überprüfen, ob unsere Site dieses Tag implementiert, um Inhalte anzuzeigen, die wir entdecken / indizieren oder indizieren möchten.
- Verfolgen Canonicals : ermöglicht es uns, kanonische Linkelemente zu verfolgen, um zu überprüfen, ob wir angeben, welche Seiten wir klassifizieren möchten.
- Verfolgen nächste / vorherige : Ermöglicht es uns, die Elemente rel = «next» und rel = «prev» zu verfolgen, um eine Vorstellung davon zu erhalten, ob unsere Site die Beziehung zwischen den Seiten klar kommuniziert.
- Auszug hreflang - Zeigt die Hreflang-Sprache, die Regionalcodes und die URL an, um zu überprüfen, ob wir die verschiedenen Variationen unserer Website kommunizieren.
- Verfolgen Sitemaps Verknüpftes XML : ermöglicht es uns, URLs in zu entdecken Sitemaps XML.
- Automatische Erkennung von XML-Sitemaps über robots.txt : ermöglicht es uns zu finden Sitemaps erkennbar durch robots.txt

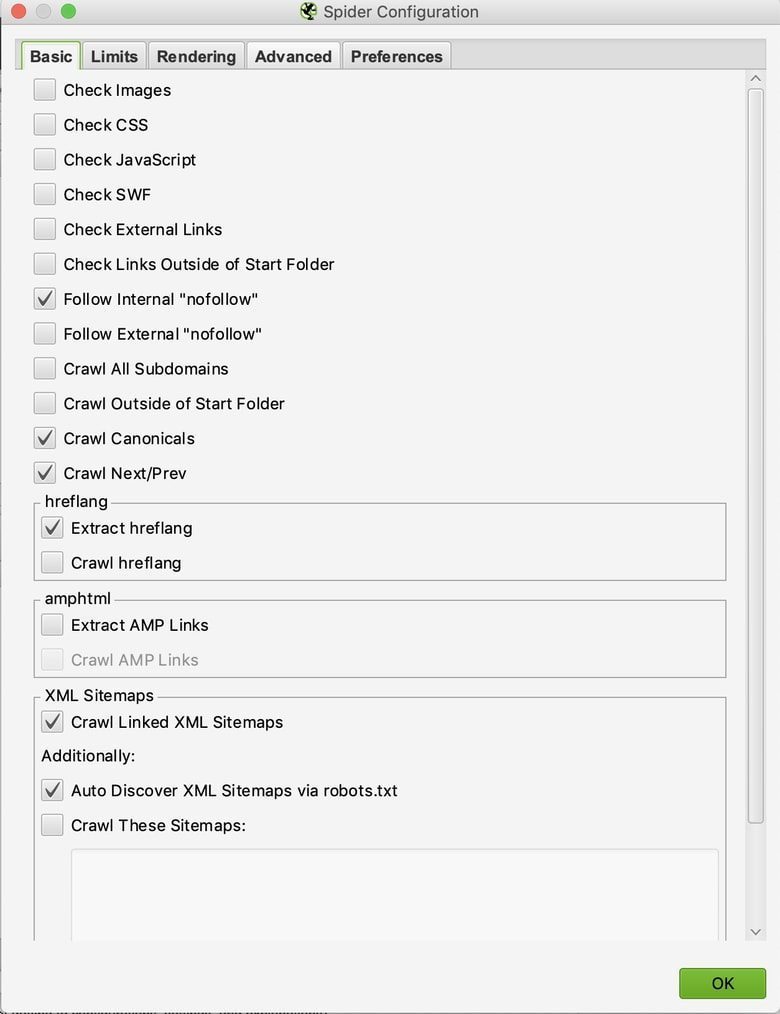
Wenn Sie mit einer Site arbeiten, die JavaScript verwendet und die interne Navigation überprüfen möchten, müssen Sie einen separaten Crawl mit unterschiedlichen Einstellungen für diese bestimmte Seite ausführen, nicht für die gesamte Domain. Navigieren Sie zur Registerkarte "Rendern", um sicherzustellen, dass unser Crawler diese Instanzen finden kann.
Einstellungen> Spider> Basic> Gerendert

Nach dem Einrichten von Spinnen müssen wir immer benutzerdefinierte Filter für bestimmte Dinge festlegen, die in unserem Crawl angezeigt werden sollen.
Einstellungen> Benutzerdefiniert> Suchen
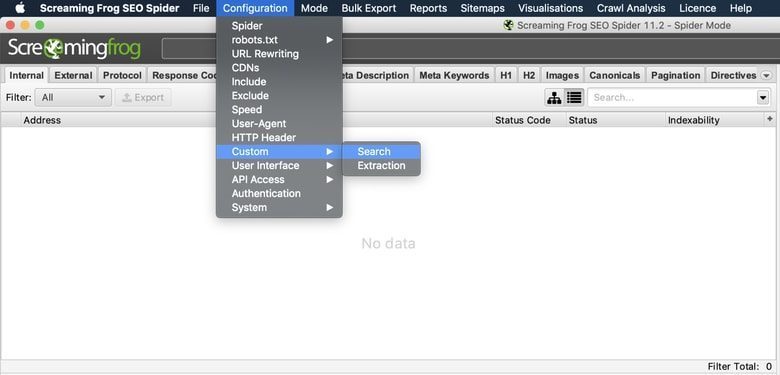
Ich verwende diese Filter regelmäßig, um Dinge einzuschließen und auszuschließen, die ich im Auge behalten möchte, und um sicherzustellen, dass alle Seiten berücksichtigt werden:
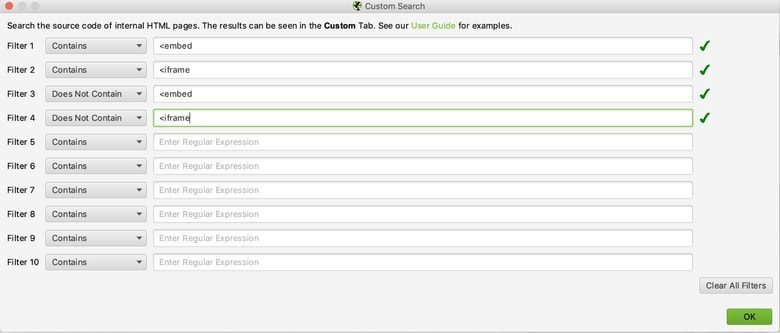
Nachdem Sie Ihre Einstellungen für das erste Crawlen konfiguriert haben, können Sie diese Einstellungen für zukünftige Crawls speichern, damit Sie diesen Vorgang nicht jedes Mal ausführen müssen. Laden Sie einfach die Einstellungen, die Sie benötigen, bevor Sie jeden Crawl ausführen.
Datei> Einstellungen> Speichern unter ...
Datei> Einstellungen> Laden ...
Verfolgen Sie Ihre erste Site
Nachdem wir unser System konfiguriert und unsere Konfigurationen vorgenommen haben, müssen wir nur noch mit dem Crawlen unserer Website beginnen!
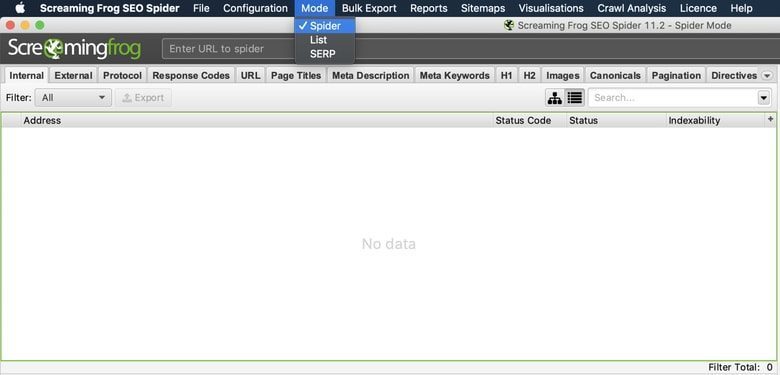
Um eine Website zu crawlen, sollten Sie den Standardmodus "Spider" von Screaming Frogs verwenden.
Modus> Spinne> URL eingeben> Klicken Sie auf Start

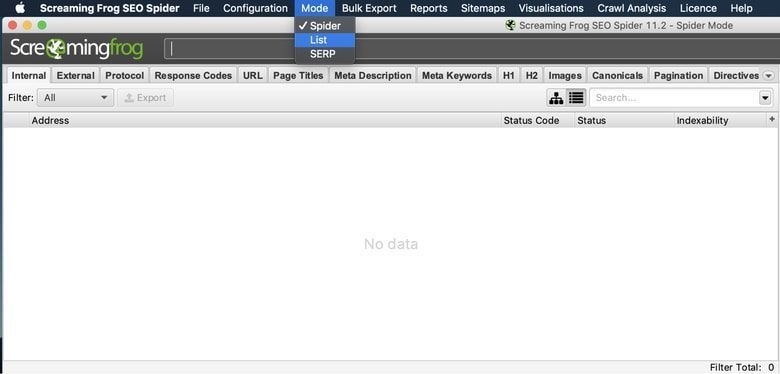
Zusätzlich zum Spider-Modus verwende ich auch den "List" -Modus, der eine Liste von URLs verfolgt, die aus einer Datei oder einem einfachen Kopieren und Einfügen stammen können. In diesem Beispiel verwenden wir eine Web-Sitemap.
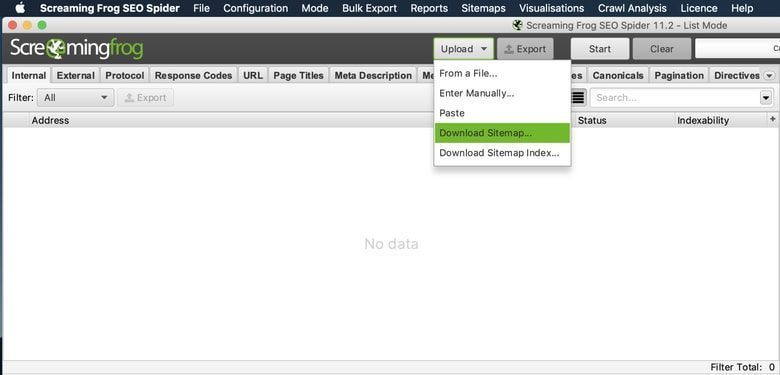
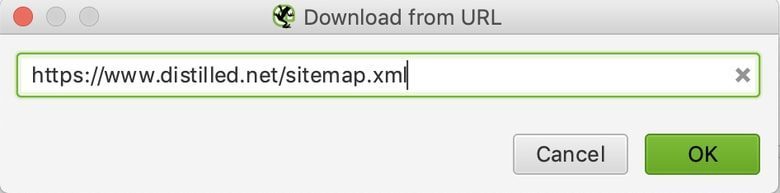
Modus> Liste> Hochladen> Sitemap herunterladen
Wichtige Dinge, die Sie beim Crawlen beachten sollten:
- Sie können den Scan nach Bedarf stoppen und fortsetzen.
- Wenn Sie das System ausschalten oder Screaming Frog beenden, gehen Ihre Daten verloren.
- Sie können Ihre Ablaufverfolgung jederzeit speichern und fortsetzen, um sie später zu beenden.
Nach dem Crawlen unserer Website ist es Zeit, die von uns gesammelten Daten zu verwenden und ihr einen kleinen Kontext zu geben.
Wenn Sie Ihre erste Erfahrung mit Screaming Frog teilen möchten, eine Frage oder einen Kommentar haben oder diese hilfreich fanden, hinterlassen Sie unten einen Kommentar!





