

Lograr una arquitectura similar a SPA en aplicaciones de varias páginas mediante la combinación de parciales, trabajadores de servicio y transmisiones.
Actualizado
Confiabilidad de la red
Aplicación de una sola página (SPA) es un patrón arquitectónico en el que el navegador ejecuta código JavaScript para actualizar la página existente cuando el usuario visita una sección diferente del sitio, en lugar de cargar una página nueva completa.
Esto significa que la aplicación web no realiza una recarga de página real. los API de historial se utiliza en su lugar para navegar de un lado a otro a través del historial del usuario y manipular el contenido de la pila del historial.
El uso de este tipo de arquitectura puede proporcionar una aplicación shell UX eso es rápido, confiable y, por lo general, consume menos datos al navegar.
En las aplicaciones de varias páginas (MPA), cada vez que un usuario navega a una nueva URL, el navegador genera progresivamente HTML específico para esa página. Esto significa una actualización de página completa cada vez que visita una nueva página.
Si bien ambos son modelos igualmente válidos para usar, es posible que desee llevar algunos de los beneficios del shell de aplicaciones UX de SPA a su sitio MPA existente. En este artículo analizaremos cómo puede lograr una arquitectura similar a SPA en aplicaciones de varias páginas combinando parciales, trabajadores de servicio y transmisiones.
Caso de producción
DEV es una comunidad donde los desarrolladores de software escriben artículos, participan en debates y crean sus perfiles profesionales.
Su arquitectura es una aplicación de varias páginas basada en plantillas de backend tradicionales a través de Ruby on Rails. Su equipo estaba interesado en algunos de los beneficios de un modelo de shell de aplicación, pero no quería emprender un cambio arquitectónico importante o alejarse de su pila tecnológica original.
Así es como funciona su solución:
- Primero, crean parciales de su página de inicio para el encabezado y el pie de página (
shell_top.htmlyshell_bottom.html) y publicarlos como fragmentos de HTML independientes con un punto final. Estos activos se agregan a la caché en el trabajador del servicio.installevento (lo que comúnmente se denomina almacenamiento en caché). - Cuando el trabajador del servicio intercepta una solicitud de navegación, crea un respuesta transmitida combinando el encabezado y pie de página almacenados en caché con el contenido de la página principal que acaba de llegar desde el servidor. El cuerpo es la única parte real de la página que requiere obtener datos de la red.
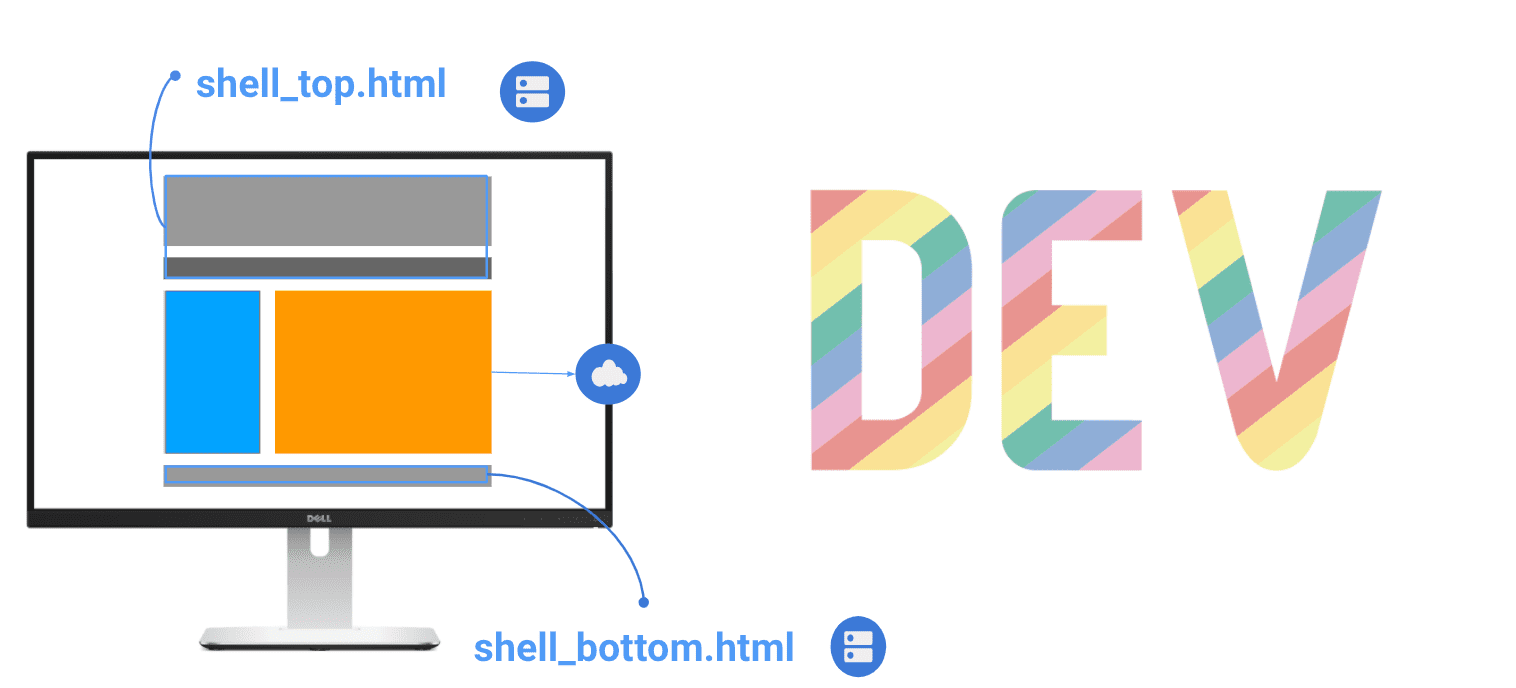
El elemento clave de esta solución es el uso de corrientes, que permite creaciones y actualizaciones incrementales de fuentes de datos. La API Streams también proporciona una interfaz para leer o escribir fragmentos de datos asincrónicos, de los cuales solo un subconjunto puede estar disponible en la memoria en un momento dado. De esta manera, el encabezado de la página se puede representar tan pronto como se selecciona de la caché, mientras que el resto del contenido se obtiene de la red. Como resultado, la experiencia de navegación es tan rápida que los usuarios no perciben una actualización de página real, solo se actualiza el nuevo contenido (el cuerpo).
La experiencia de usuario resultante es similar al patrón de experiencia de usuario de shell de aplicaciones de SPA, implementado en un sitio de MPA.
La sección anterior contiene un resumen rápido de la solución de DEV. Para obtener una explicación más detallada, consulte su entrada en el blog sobre este tema.
Implementar una arquitectura de UX de shell de aplicaciones en MPA con Workbox
En esta sección, cubriremos un resumen de las diferentes partes involucradas en la implementación de una arquitectura de UX de shell de aplicación en MPA. Para obtener una publicación más detallada sobre cómo implementar esto en un sitio real, consulte Más allá de los SPA: arquitecturas alternativas para su PWA.
El servidor
Parciales
El primer paso es adoptar una estructura de sitio basada en HTML parciales. Estas son solo piezas modulares de sus páginas que se pueden reutilizar en su sitio y también se pueden entregar como fragmentos de HTML independientes.
los cabeza parcial puede contener toda la lógica necesaria para diseñar y representar el encabezado de la página. los barra de navegación parcial puede contener la lógica de la barra de navegación, el pie de página parcial el código que necesita ejecutarse allí, y así sucesivamente.
La primera vez que el usuario visita el sitio, su servidor genera una respuesta ensamblando las diferentes partes de la página:
app.get(routes.get('index'), async (req, res) => {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(…);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});Usando el res (respuesta) del objeto método de escrituray haciendo referencia a plantillas parciales almacenadas localmente, la respuesta puede ser transmitido inmediatamente, sin ser bloqueado por ninguna fuente de datos externa. El navegador toma este HTML inicial y muestra una interfaz significativa y un mensaje de carga de inmediato.
La siguiente parte de la página utiliza datos de API, lo que implica una solicitud de red. La aplicación web no puede procesar nada más hasta que recibe una respuesta y la procesa, pero al menos los usuarios no están mirando una pantalla en blanco mientras esperan.
El trabajador de servicio
La primera vez que un usuario visita un sitio, el encabezado de la página se representará más rápido, sin tener que esperar el cuerpo de la página. El navegador todavía necesita ir a la red para buscar el resto de la página.
Después de la carga de la primera página, el trabajador del servicio se registra, lo que le permite obtener los parciales para las diferentes partes estáticas de la página (encabezado, barra de navegación, pie de página, etc.) desde la caché.
Precaching activos estáticos
El primer paso es almacenar en caché las plantillas HTML parciales, para que estén disponibles de inmediato. Con Precargado de la caja de trabajo puede almacenar estos archivos en el install evento del trabajador del servicio y manténgalos actualizados cuando se implementen cambios en la aplicación web.
Dependiendo del proceso de compilación, Workbox tiene diferentes soluciones para generar un trabajador de servicio e indicar la lista de archivos a precargar, incluyendo paquete web y trago complementos, un módulo de nodejs genérico y un interfaz de línea de comandos.
Para una configuración parcial como la descrita anteriormente, el archivo de trabajador de servicio resultante debe contener algo similar a lo siguiente:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
]);Transmisión
A continuación, agregue la lógica del trabajador de servicio para que el HTML parcial almacenado en caché se pueda enviar de vuelta a la aplicación web de inmediato. Esta es una parte crucial para ser rápido y confiable. Utilizando la API de Streams dentro de nuestro trabajador de servicio lo hace posible.
Flujos de Workbox abstrae los detalles de cómo funciona la transmisión. El paquete le permite pasar a la biblioteca una combinación de fuentes de transmisión, tanto de cachés como de datos en tiempo de ejecución que pueden provenir de la red. Workbox se encarga de coordinar las fuentes individuales y unirlas en una única respuesta de transmisión.
Primero, configure las estrategias en Workbox para manejar las diferentes fuentes que conformarán la respuesta de transmisión.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [
new workbox.expiration.Plugin({maxEntries: 50}),
],
});
A continuación, dígale a Workbox cómo usar las estrategias para construir una respuesta de transmisión completa, pasando una serie de fuentes como funciones para ejecutar de inmediato:
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'}),
() => cacheStrategy.makeRequest({request: '/navbar.html'}),
async ({event, url}) => {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(…);
const data = await listResponse.json();
return templates.index(tag, data.items);
},
() => cacheStrategy.makeRequest({request: '/foot.html'}),
]);- Las dos primeras fuentes son plantillas parciales almacenadas en caché leídas directamente desde la caché del trabajador del servicio, por lo que siempre estarán disponibles de inmediato.
- La siguiente función de origen obtiene datos de la red y procesa la respuesta en el HTML que espera la aplicación web.
- Finalmente, se transmite una copia en caché del pie de página y las etiquetas HTML de cierre para completar la respuesta.
Workbox toma el resultado de cada fuente y lo transmite a la aplicación web, en secuencia, solo retrasándose si la siguiente función en la matriz aún no se ha completado. Como resultado, el usuario ve inmediatamente la página que se está pintando. La experiencia es tan rápida que al navegar el encabezado se queda en su posición sin que el usuario perciba la actualización de la página completa. Esto es muy similar a la UX que proporciona el modelo SPA de shell de la aplicación.




